| CPC G06V 20/49 (2022.01) [G06F 18/2148 (2023.01); G06F 18/22 (2023.01); G06N 3/045 (2023.01); G06V 10/426 (2022.01); G06V 20/41 (2022.01); H04N 21/23418 (2013.01)] | 20 Claims |
|
1. A method for automated media segmentation carried out by a computing system, the method comprising:
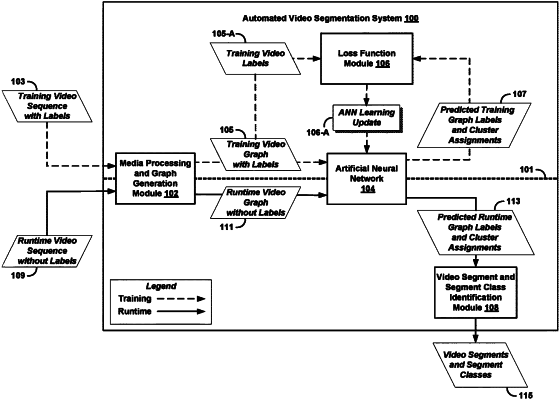
receiving a training sequence of training media frames comprising a plurality of respective training media segments, wherein the respective training media segments comprise non-overlapping respective sub-sequences of the training media frames, each of the respective sub-sequences being associated with respective contextually-related subject content, and wherein each training media frame is associated with a respective label identifying both which particular training media segment it belongs to, and a segment class associated with the particular training media segment;
analytically constructing a training media graph from the training sequence of training media frames, the training media graph comprising nodes connected by edges, wherein each node corresponds to a different one of the respective training media frames, and each edge connects a different particular pair of nodes, and is associated with both a temporal distance between the respective training media frames corresponding to the particular pair of nodes, and a respective similarity metric quantifying similarity between respective features of the respective training media frames corresponding to the particular pair of nodes;
training an artificial neural network (ANN) to compute both (i) a predicted training label for each node of the training media graph, and (ii) predicted clusters of the nodes corresponding to predicted membership among the respective training media segments of the corresponding training media frames, using the training media graph as input to the ANN, and ground-truth clusters of ground-truth labeled nodes, wherein the ground-truth labeled nodes correspond to the training media frames and their associated respective labels, and the ground-truth clusters correspond to the respective training media segments;
further training the ANN to compute a predicted segment class for each of the predicted clusters, using as ground truths the segment classes of the respective training media segments; and
configuring the trained ANN for application to one or more unseen runtime media sequences.
|