| CPC G06V 20/20 (2022.01) [G06F 18/214 (2023.01); G06F 18/2415 (2023.01); G06V 10/454 (2022.01); G06V 10/764 (2022.01); G06V 10/774 (2022.01); G06V 10/82 (2022.01); G06V 20/41 (2022.01); G06V 20/46 (2022.01)] | 21 Claims |
|
1. An object locator, comprising:
processing circuitry; and
memory comprising instructions executable by the processing circuitry whereby the object locator is operative to:
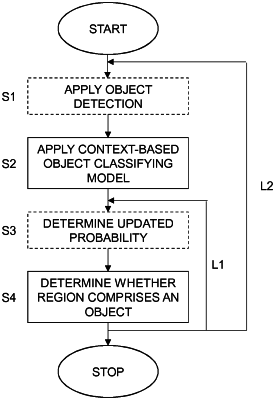
apply, for at least one frame of a video stream, a context-based object classifying model to a set of object location representations, derived from an object detection applied to the at least one frame, to obtain a context-adapted classification probability for each object location representation of the set; wherein each object location representation of the set defines a region of the at least one frame; wherein each context-adapted classification probability represents a likelihood that the region of the at least one frame defined by the object location representation comprises an object; wherein the context-based object classifying model is generated based on object location representations from previous frames of the video stream; and
determine, for each object location representation of at least a portion of the set, whether the region of the at least one frame defined by the object location representation comprises an object based on the context-adapted classification probability and a detection probability;
wherein the detection probability is derived from the object detection and represents a likelihood that the region of the at least one frame defined by the object location representation comprises an object.
|