| CPC G06V 10/454 (2022.01) [G06T 7/80 (2017.01); G06V 10/774 (2022.01)] | 5 Claims |
|
1. A method for identifying and ranging inland vessels, characterized in that the inland vessel identification and ranging method comprises:
in a stage of vessel target identification, a MobileNetV1 network is used as a feature extraction module of a YOLO-V4 network model; in a stage of vessel target ranging, a sub-pixel level feature point detection and matching algorithm is proposed based on an ORB algorithm, and a FSRCNN algorithm is used for super-resolution reconstruction of an original low resolution image; in a stage of vessel identification, based on the YOLO-V4 network model, the MobileNetV1 network is used to replace the feature extraction network CSPDarknet53 of the YOLO-V4 network model; in a stage of vessel ranging, a binocular stereo vision ranging model is established, and the FSRCNN is used for super-resolution reconstruction of the original low resolution image pairs to enhance the vessel feature information; the ORB algorithm is used to achieve feature detection and matching at the sub-pixel level to obtain a parallax value between image pairs, and a depth information of the vessel target is obtained by triangulation principle and coordinate conversion;
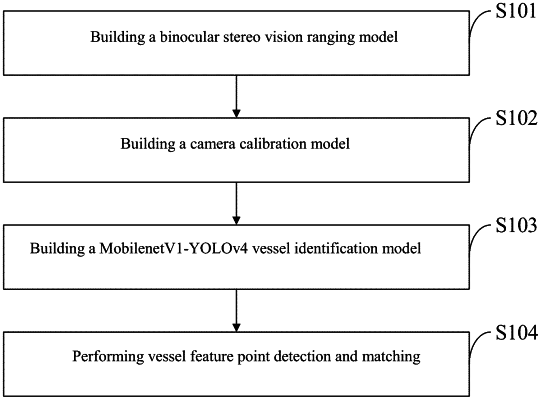
The said method for identifying and ranging inland vessels comprises the following steps:
Step 1: Building a binocular stereo vision ranging model;
Step 2: Building a camera calibration model;
Step 3: Building a MobilenetV1-YOLOv4 vessel identification model;
Step 4: Performing vessel feature point detection and matching;
a vessel feature point detection and matching in Step 4 includes:
the FSRCNN model consists of five parts: feature extraction, reduction, mapping, amplification and deconvolution; The first four parts are convolutional layers, and the last part is deconvolution layers;
the FSRCNN directly takes the original low resolution image as an input, and uses a linear rectification function PReLU as the activation function; the FSRCNN uses d 5×5 sized convolutional kernel for feature extraction, s 1×1 sized convolutional kernel for shrinkage, m 3×3 sized convolutions concatenated as mapping layers, and d 1×1 sized convolutional kernels for expansion; At the end of a FSRCNN network, one 9×9 sized convolutional kernel is used for deconvolution to obtain high-resolution images;
PReLU is shown as in the following equation:
 a mean square error is used as the loss function during a FSRCNN training, as shown in the following equation:
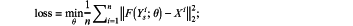 Where, Ysi and Xi are i-th pair of super-resolution images and low-resolution images in a training data, respectively; F(Ysi;θ) is a FSRCNN network output, θ is a hyperparameter in the FSRCNN network;
the ORB algorithm is used to create feature vectors for a key feature points in the super-resolution image, in order to identify corresponding targets in the super-resolution image, including following steps:
(1) Feature point extraction
the ORB algorithm uses a FAST algorithm to find the feature points in the image; if a pixel in the super-resolution image differs from neighboring pixels, then that pixel is the feature point; specific steps are as follows:
1) select a pixel point P in the super-resolution image to be detected, with a pixel value of IP and a circle centered on P with a radius of 3; There are 16 pixels on the determined circle, represented as P1, P2, . . . , P16, respectively;
2) Determine a threshold: t;
3) Calculate difference between all pixel values on the determined circle and the pixel values of P; If there are consecutive N points on the circle that satisfy a following equation, where Ix represents a point among the 16 pixels on the circle, then the point Ix is used as a candidate point, let N=12; For each pixel, the 1st, 9th, 5th, and 13th pixel points among the 16 pixels on the circle are detected; If at least three of the 1st, 9th, 5th, and 13th pixel points meet the following equation, the points are candidate detection points, and maximum suppression is used to delete excess candidate points
 (2) BRIEF descriptor creation
ORB algorithm uses BRIEF to create binary descriptors for a detected key feature point, describing feature vectors that only contain 0 and 1; specific steps are as follows:
The image to be detected is processed by Gaussian filter;
2) BRIEF takes the candidate feature point P′ as a center point, takes a S×S sized area, randomly selects two points Px′ and Py′ within the area, compares pixel sizes of the two points, and assigns the following values:
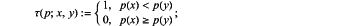 Where, Px′ and Py′ are pixel values of random points x(u1,v1) and y(u2,v2) in the area, respectively;
3) randomly select n pixel pairs in the area of S×S and repeat binary assignment; an encoding process is a description of the key feature points in the super-resolution image, which is a feature descriptor; a value of n is 128, 256 or 512; image features are described by n-bit binary vectors:
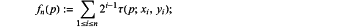 the ORB algorithm has a characteristic of invariant rotation, using a direction θ′ of key feature points to rotate the BRIEF descriptor; a specific process is as follows:
1) for any feature point in the super-resolution image, n pairs of pixel values located (xi,yi) within a S×S neighborhood are represented by a 2×n matrix:
 2) the direction θ′ of the key feature points obtained using the FAST algorithm: using a neighborhood circle of corner point P″ as an image block B, define a moment of the image block B as:
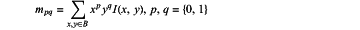 find a centroid of the image block B:
 connect a geometric center O of the image block with the centroid C to obtain a direction vector OC; At this point, the direction of the key feature points is defined as: θ′=arctan(m01/m10);
3) Calculate a corresponding rotation matrix Rθ and S:
from the direction of the key feature points calculated in Step 2), it can be seen that:
 -therefore, Sθ=RθS;
4) calculate a rotation descriptor:
gn(p,θ):=fn(p)|(xi,yi)∈Sθ
where,
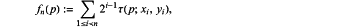 is the descriptor of BRIEF; thus, the rotation invariance of the ORB algorithm is achieved;
Feature point matching:
calculate a Hamming distance between the feature descriptors in an image alignment, which means calculating a similarity between the key feature points if it is less than a given threshold, then two key feature points will be matched.
|