| CPC G06T 7/248 (2017.01) [G05D 1/0221 (2013.01); G05D 1/0246 (2013.01); G06N 3/045 (2023.01); G06N 3/08 (2013.01); G06T 7/50 (2017.01); G06T 7/55 (2017.01); G06T 7/73 (2017.01); G06T 2207/10024 (2013.01); G06T 2207/20081 (2013.01); G06T 2207/20084 (2013.01)] | 17 Claims |
|
12. A method, comprising:
jointly training a machine-learning-based monocular optical flow, depth, and scene flow estimator by:
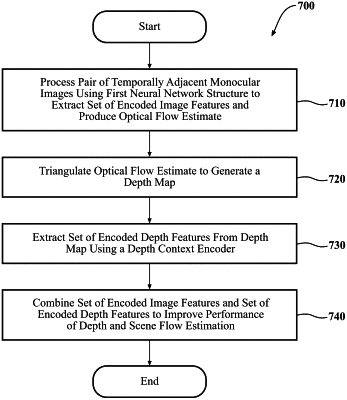
processing a pair of temporally adjacent monocular image frames using a first neural network structure to produce an optical flow estimate and to extract, from at least one image frame in the pair of temporally adjacent monocular image frames, a set of encoded image context features;
triangulating the optical flow estimate to generate a depth map;
extracting a set of encoded depth context features from the depth map using a depth context encoder; and
combining the set of encoded image context features and the set of encoded depth context features to improve performance of a second neural network structure in estimating depth and scene flow, wherein the processing the pair of temporally adjacent monocular image frames using the first neural network structure to produce the optical flow estimate and to extract, from the at least one image frame in the pair of temporally adjacent monocular image frames, the set of encoded image context features includes:
extracting the set of encoded image context features using a Red-Green-Blue (RGB) context encoder;
extracting a set of encoded image features from the pair of temporally adjacent monocular image frames using a RGB encoder;
processing the set of encoded image features using a correlation layer to generate a correlation volume; and
refining iteratively an initial estimate of optical flow based, at least in part, on the set of encoded image context features using a Gated-Recurrent-Units-based update operator and the correlation volume.
|