| CPC G06T 1/20 (2013.01) [G06F 7/483 (2013.01); G06F 9/30014 (2013.01); G06F 9/30185 (2013.01); G06F 9/3863 (2013.01); G06F 9/5044 (2013.01); G06N 3/044 (2023.01); G06N 3/045 (2023.01); G06N 3/063 (2013.01); G06N 3/084 (2013.01); G06N 20/00 (2019.01); G06F 3/14 (2013.01); G06T 1/60 (2013.01); G06T 15/005 (2013.01)] | 20 Claims |
|
1. An apparatus, comprising:
a memory stack including multiple memory dies; and
a parallel processor including a plurality of multiprocessors, each multiprocessor having a single instruction, multiple thread (SIMT) architecture, the parallel processor coupled to the memory stack via one or more memory interfaces, at least one multiprocessor comprising:
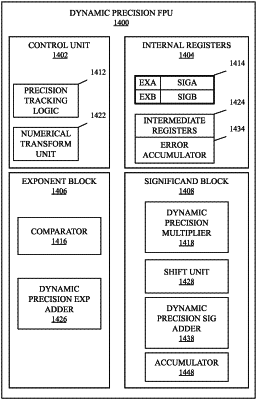
a multiply-accumulate circuit to perform operations including multiply-accumulate operations on matrix data in a first layer of a neural network implementation to produce a result matrix comprising a plurality of matrix data elements at a first precision, wherein the multiply-accumulate operations include a matrix multiplication operation with values smaller than 32 bits and an accumulate operation having a 32-bit input;
precision tracking logic to dynamically evaluate metrics associated with the matrix data elements and, based on the metrics, to indicate if an optimization is to be performed to represent data at a second layer of the neural network implementation, wherein the optimization includes to apply a numerical transform operation to the data to enable representation of the data at the second layer at a second precision; and
a numerical transform unit to dynamically perform the numerical transform operation on the matrix data elements, based on the indication, to produce transformed matrix data elements at the second precision, wherein the second precision is lower than the first precision.
|