| CPC G06Q 30/0201 (2013.01) [G06F 16/221 (2019.01); G06F 16/24535 (2019.01); G06F 17/16 (2013.01); G06F 18/214 (2023.01); G06N 5/04 (2013.01)] | 20 Claims |
|
1. A computer-implemented method, comprising:
obtaining, from a user device, a Structured Query Language (SQL) query to create a matrix factorization model based on a set of training data, the SQL query comprising:
a model type; and
a source of the set of training data;
generating, using the SQL query, a plurality of SQL sub-queries; and
executing the plurality of SQL sub-queries;
based on executing the plurality of SQL sub-queries:
obtaining the set of training data from the source;
determining, based on the set of training data, a model vector;
determining, based on the set of training data, a data vector;
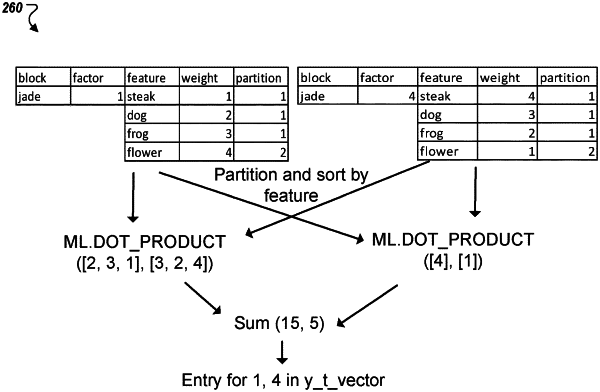
pre-ordering the model vector and the data vector;
determining, based on a maximum number of floats for the pre-ordered model vector and the pre-ordered data vector, a partition index;
partitioning, based on the partition index, the pre-ordered model vector into a first pre-ordered model sub-vector and a second pre-ordered model sub-vector;
partitioning, based on the partition index, the pre-ordered data vector into a first pre-ordered data sub-vector and a second pre-ordered data sub-vector;
determining a first dot product between the first pre-ordered model sub-vector and the first pre-ordered data sub-vector and a second dot product between the second pre-ordered model sub-vector and the second pre-ordered data sub-vector;
generating the matrix factorization model based on the first dot product and the second dot product; and
executing the matrix factorization model.
|