| CPC G06N 3/044 (2023.01) [G06N 3/049 (2013.01); G06N 3/08 (2013.01); G06N 20/00 (2019.01); G05B 2219/33025 (2013.01); G05B 2219/40326 (2013.01); G06F 17/16 (2013.01); G06N 3/04 (2013.01); G06N 3/084 (2013.01)] | 22 Claims |
|
1. A computer-implemented method that, when executed on data processing hardware, causes the data processing hardware to perform operations comprising:
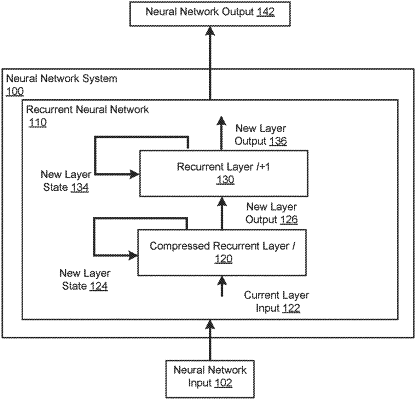
re-configuring an uncompressed version of a trained recurrent neural network (RNN) to generate a compressed version of the trained RNN by replacing a particular uncompressed trained recurrent layer of a plurality of uncompressed recurrent layers of the uncompressed version of the trained RNN with a corresponding compressed trained recurrent layer by:
generating a first compressed weight matrix, Zhl, and a projection matrix, Pl, based on an uncompressed recurrent weight matrix, Wh, containing trained recurrent weights for the particular uncompressed trained recurrent layer of the trained RNN;
generating a second compressed weight matrix, Zxl, based on the first compressed weight matrix, Zhl, and the projection matrix, Pl; and
generating, based on a product of the first compressed weight matrix, Zhl, and the projection matrix, Pl, a compressed trained recurrent weight matrix that replaces the uncompressed recurrent weight matrix, Wh, in the corresponding compressed trained recurrent layer, the compressed trained recurrent weight matrix comprising fewer parameters than the uncompressed recurrent weight matrix, Wh; and
transmitting the compressed version of the trained RNN having the the corresponding compressed trained recurrent layer to a device, the compressed version of the trained RNN having the corresponding compressed trained recurrent layer configured to receive a respective neural network input at each of multiple time steps and generate a respective neural network output at each of the multiple time steps,
wherein, after compressing the particular uncompressed trained recurrent layer of the plurality of uncompressed recurrent layers, the compressed version of the trained RNN comprises fewer parameters than the uncompressed version of the trained RNN.
|