| CPC G06N 3/04 (2013.01) [G06N 3/045 (2023.01); G06N 3/063 (2013.01); H04B 1/16 (2013.01)] | 18 Claims |
|
1. A three dimensional neural network accelerator comprising:
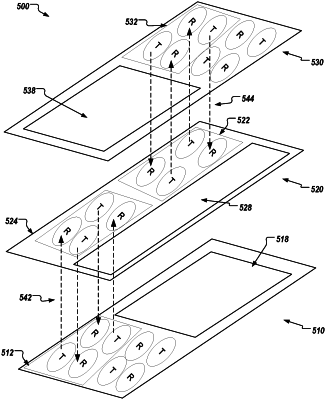
a first neural network accelerator chip comprising a first array of tiles that includes a first neural network accelerator tile comprising a first transmission coil; and
a second neural network accelerator chip comprising a second array of tiles that includes a second neural network accelerator tile comprising a second transmission coil,
wherein each tile of the first array of tiles and the second array of tiles can independently execute computations for the three dimensional neural network accelerator and includes a processing element and a memory,
wherein the first neural network accelerator tile is adjacent to and aligned with the second neural network accelerator tile,
wherein the first transmission coil is configured to establish wireless communication with the second transmission coil via inductive coupling,
wherein the first array of tiles and the second array of tiles are configured to accelerate a computation of a neural network by forming, through wireless communication established between the first transmission coil of the first neural network accelerator tile and the second transmission coil of the second neural network accelerator tile, an interconnect system configured to provide for a flow of data, wherein the first transmission coil provides an interconnection between the first neural network accelerator tile and the second neural network accelerator tile through Near Field Wireless Communication and wherein the flow of data is according to a sequence of processing through the first array of tiles and the second array of tiles, and
wherein the sequence of processing starts and ends in a controller, the controller comprising one or more functional blocks configured to handle one or more of: (i) input/output (I/O) to a host computer, (ii) interface to memory, (iii) connecting to I/O devices, or (iv) performing synchronization, coordination, or buffer functions.
|