| CPC G06F 40/263 (2020.01) | 20 Claims |
|
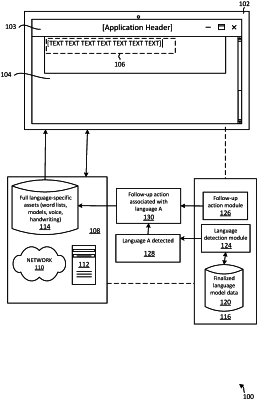
1. A computer-implemented method for training a language detection model to detect a language of text, the method comprising:
a first training phase, comprising:
identifying a list of tokens from a corpus, the identifying comprising:
extracting affixes from each word in the corpus and storing each unique affix as a token in the list of tokens; and
identifying word stems after the extracting the affixes and storing each unique word stem as a token in the list of tokens; and
a second training phase, comprising:
assigning weights from the corpus to the list of tokens by training the list of tokens against the corpus using a weighting engine.
|