| CPC G06F 21/6218 (2013.01) | 14 Claims |
|
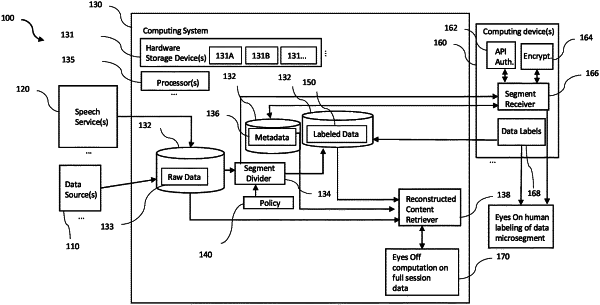
1. A method implemented by a computing system for securing data access of machine learning training data at a plurality of distributed computing devices, the method comprising:
the computing system receiving electronic content comprising original data;
the computing system determining a security level associated with the electronic content;
the computing system determining a microsegment duration based on the determined security level;
the computing system selectively dividing the electronic content into a plurality of microsegments according to the microsegment duration determined based on the determined security level;
the computing system identifying a plurality of destination computing devices configured to apply a plurality of labels corresponding to the plurality of microsegments;
the computing system determining a threshold quantity of microsegments based on the determined security level;
the computing system restrictively distributing the plurality of microsegments to the plurality of destination computing devices in accordance with the threshold quantity of microsegments determined based on the determined security level, wherein the restricted distribution includes restricting a quantity of microsegments to be distributed to any one of the destination computing devices to less than the threshold quantity of microsegments determined based on the determined security level;
the computing system receiving a plurality of labels corresponding to plurality of microsegments divided from the electronic content, the plurality of labels being provided by at least two of the plurality of destination computing devices;
the computing system reconstructing the plurality of microsegments into reconstructed electronic content comprising the plurality of labels corresponding the plurality of microsegments, wherein the reconstructed electronic content further comprises microsegments that are divided to include portions of microsegments that overlap each other, wherein the reconstructed electronic content comprises training data for a machine learning model;
the computing system determining that at least one overlapped portion of microsegments includes a set of non-equivalent corresponding labels; and
the computing system selecting a particular label of the set of non-equivalent corresponding labels for inclusion in the reconstructed electronic content for the overlapped portion of microsegments.
|