| CPC G06F 16/2471 (2019.01) [G06F 16/219 (2019.01); G06F 16/285 (2019.01)] | 20 Claims |
|
1. A method, comprising:
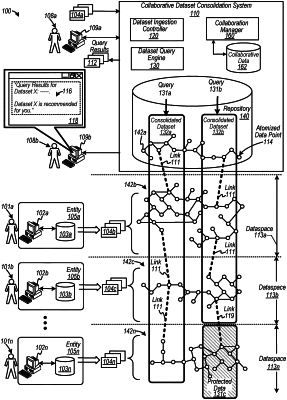
identifying via a network one or more distributed data repositories associated with distributed computer networks, at least one distributed data repository including a cloud-based data store configured to store one or more atomized datasets in a triple data format;
causing to load via the network into the cloud-based data store the one or more atomized datasets in the triple data format; and
implementing one or more portions of an application associated with the distributed computer networks to generate one or more queries, the one or more portions of the application configured to perform data operations associated with a dataset including:
converting the dataset from a first data format to the triple data format, which is configured to form a portion of a graph;
selecting a data store type associated with the cloud-based data store based on the at least one resource requirement;
performing a load operation associated with the one or more atomized datasets as a function of the cloud-based data store based on the at least one resource requirement;
receiving a query to access the dataset;
classifying at least a portion of the query directed to the dataset to determine a classification type, whereby the classification type is associated with a type of query for a query portion; and
applying the portion of the query as a sub-query to the one or more distributed data repositories including the cloud-based data store configured to store the dataset as at least one atomized dataset in the triple data format.
|