| CPC H04N 21/4627 (2013.01) [G10L 15/063 (2013.01); G10L 21/028 (2013.01); G10L 25/57 (2013.01); G10L 25/81 (2013.01); H04N 21/439 (2013.01)] | 3 Claims |
|
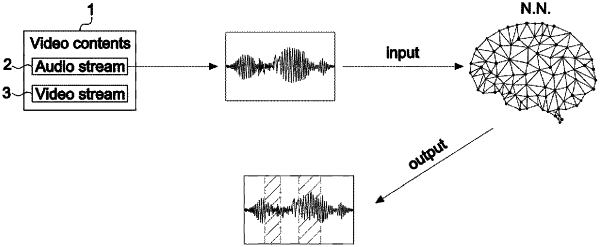
1. A data processing method comprising:
receiving video content including a video stream and an audio stream;
detecting music data from the audio stream; and
filtering the audio stream to remove the music data detected from the audio stream,
wherein the detecting of the music data from the audio stream comprises a division operation of dividing the audio stream into music data and voice data and a detection operation of detecting a section in which the music data exists from the audio stream,
wherein the division operation is performed by a first artificial intelligence (AI) model which is trained in advance,
wherein the first AI model, which is composed of an artificial neural network that performs deep learning or machine learning, is configured to perform learning using training data labeled as music or voice,
wherein the first AI model is configured to output a probability that each preset unit section of the audio stream corresponds to the music data and a probability that each preset unit section of the audio stream corresponds to the voice data,
wherein the detection operation is performed by a second artificial intelligence (AI) model which is trained in advance, and
wherein the second AI model is configured to perform learning using training data identified in advance as including music or not.
|