| CPC G10L 15/26 (2013.01) [G06F 40/263 (2020.01); G06F 40/58 (2020.01); G10L 15/005 (2013.01); G10L 15/07 (2013.01)] | 11 Claims |
|
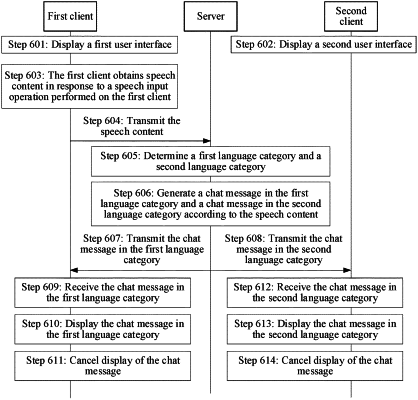
1. A method for performing speech-to-text conversion, the method comprising:
displaying, by a first device comprising a first memory storing instructions and a first processor in communication with the first memory, a first user interface, the first user interface being a display screen of a virtual environment that provides a virtual activity place for a first virtual role controlled by a first user account, the first user interface comprising a chat control;
displaying, by a second device comprising a second memory storing instructions and a second processor in communication with the second memory, a second user interface, the second user interface being a display screen of a virtual environment that provides a virtual activity place for a second virtual role controlled by a second user account;
transmitting, by the first device, a first geographic information indicating a geographical location of the first device to a server;
transmitting, by the second device, a second geographic information indicating a geographical location of the second device to the server; and
in response to an input start operation performed on the chat control, displaying, by the first device, a speech recording prompt at a peripheral position of the chat control on the first device, the speech recording prompt being for prompting a user that the first device is receiving speech content;
in response to an input end operation performed on the chat control on the first device,
canceling, by the first device, display of the speech recording prompt,
transmitting, by the first device, the received speech content to a server, for the server to generate a chat message in a first language and a chat message in a second language according to the speech content, the first language being determined based on the first geographic information, the second language is being determined based on the second geographic information, and
displaying, by the first device, the chat message in the first language after receiving the chat message in the first language that is transmitted by the server, a display position of the chat message in the first language being set by the first user account,
displaying, by the second device, the chat message in the second language after receiving the chat message in the second language that is transmitted by the server, wherein-text content of the chat message is recognized based on the speech content; and
in response to a display time of the chat message in the first language reaching a preset duration, canceling, by the first device, display of the chat message in the first language.
|