| CPC G10L 15/063 (2013.01) [G06N 3/08 (2013.01); G06N 20/00 (2019.01); G10L 15/04 (2013.01); G10L 15/16 (2013.01)] | 16 Claims |
|
1. A computer-implemented method when executed on data processing hardware causes the data processing hardware to perform operations comprising:
receiving a sequence of acoustic frames characterizing a speech conversation between two or more speakers;
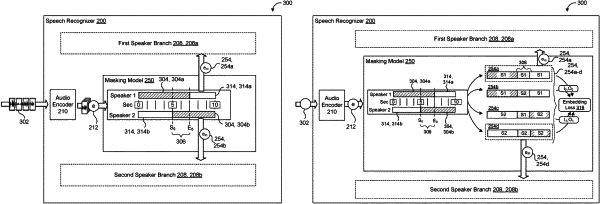
encoding, by an audio encoder of a speech recognition model, the sequence of acoustic frames into corresponding audio embeddings;
for each corresponding audio embedding:
receiving a speaker embedding associated with the corresponding audio embedding;
identifying a respective speaker among the two or more speakers that is associated with the corresponding audio embedding based on the speaker embedding;
concatenating the corresponding audio embedding with the speaker embedding; and
generating, using a masking model, a masked embedding corresponding to the identified respective speaker based on the corresponding audio embedding concatenated with the speaker embedding; and
for each respective speaker among the two or more speakers, generating, by a dedicated speaker branch of the speech recognition model for the respective speaker that receives each masked embedding corresponding to the respective speaker, a respective transcription that transcribes a respective segment of the speech conversation spoken by the respective speaker,
wherein a training process trains the masking model and the each of the dedicated speaker branches by:
in a first stage, training a single recurrent neural network-transducer (RNN-T) model using training examples;
dividing the single RNN-T model into each of the dedicated speaker branches; and
in a second stage, training the masking model and fine-tuning each of the dedicated speaker branches using the training examples by applying a respective masking loss to a segment of each training example of the training examples where a speaker is not speaking to minimize an RNN-T loss for each dedicated speaker branch of the masking model.
|