| CPC G06V 10/778 (2022.01) [G06V 10/26 (2022.01); G06V 10/751 (2022.01); G06V 10/774 (2022.01)] | 20 Claims |
|
1. A method, implemented by a computing system, comprising:
accessing a plurality of images to facilitate pre-training a first machine-learning model comprising an encoder and a decoder; and
using the plurality of images to pre-train the first machine-learning model by:
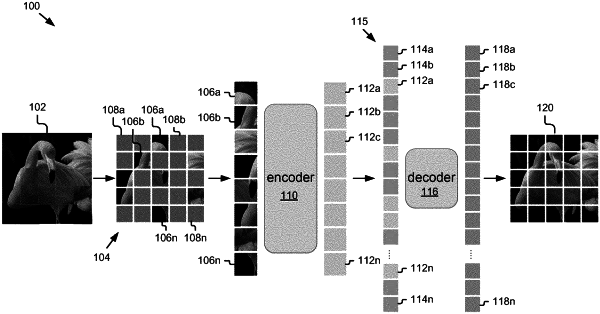
dividing at least one image, of the plurality of images, into a set of patches;
selecting a first subset of the patches to be visible and a second subset of the patches to be masked during the pre-training;
processing, using the encoder, the first subset of patches and corresponding first positional encodings to generate corresponding first latent representations;
processing, using the decoder, the first latent representations corresponding to the first subset of patches and mask tokens corresponding to the second subset of patches to generate reconstructed patches corresponding to the second subset of patches, wherein the reconstructed patches and the first subset of patches are used to generate a reconstructed image; and
updating the first machine-learning model based on comparisons between the at least one image and the reconstructed image.
|