| CPC G06F 11/203 (2013.01) [G06F 9/461 (2013.01); G06F 9/485 (2013.01); G06F 9/4856 (2013.01); G06F 9/5038 (2013.01); G06F 11/0709 (2013.01); G06F 2209/5021 (2013.01); G06F 2209/509 (2013.01)] | 8 Claims |
|
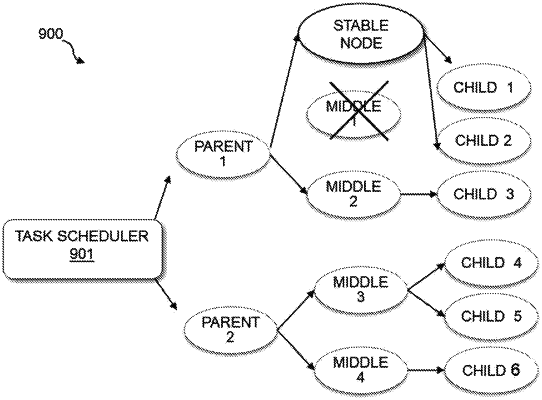
1. A computer-implemented method for task failover in a cloud environment, wherein the cloud environment includes a plurality of reclaimable nodes, comprising:
monitoring, by one or more processing units, if any node of the plurality of reclaimable nodes having one or more child nodes is to be reclaimed for executing other tasks, a reclaimable node executing in a spot instance in the cloud environment and being reclaimable at any time without delay for data storing;
determining, by one or more processing units, whether a task of the existing tasks on any node of the reclaimable nodes having one or more child nodes is recoverable, the task defined as recoverable if the task has been executed on the one or more child nodes for a period higher than a threshold and an impact will occur if associated task execution in the one or more child nodes is killed, the impact related to wasted calculations associated with task execution in the one or more child nodes;
storing, by one or more processing units, data of the recoverable task on the reclaimable node remotely in a stable node;
notifying, by one or more processing units, at least one associated task executed by at least one child node associated with a reclaimed node in the cloud environment to wait without abandoning the at least one associated task which results in a waste of calculation resources and delay of response;
connecting, by one or more processing units, the child node of the reclaimed node to the stable node which will not be reclaimed to interrupt task execution; and
continuing execution of the recoverable task and the at least one associated task on the stable node.
|