| CPC G10L 15/20 (2013.01) [G06F 3/165 (2013.01); G06F 3/167 (2013.01); G10L 15/222 (2013.01); G10L 17/06 (2013.01); G10L 21/034 (2013.01); G10L 25/84 (2013.01); H03G 3/3005 (2013.01); G10L 15/26 (2013.01); G10L 17/00 (2013.01)] | 20 Claims |
|
1. A computer-implemented method when executed on data processing hardware causes the data processing hardware to perform operations comprising:
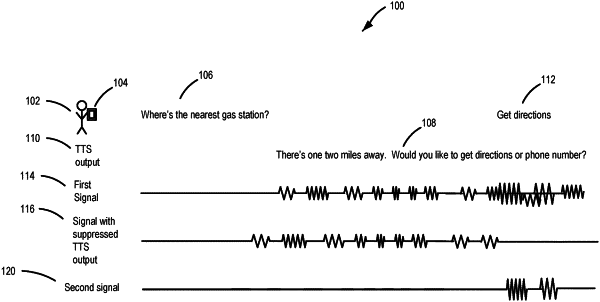
while audio is being played back from a computing device, receiving a first audio signal captured by a microphone of the computing device, the first audio signal comprising the played back audio and speech audio corresponding to a query, the played back audio different than the speech audio corresponding to the query;
processing, using a neural network-based model, the first audio signal to determine that the speech audio corresponding to the query was spoken by a user of the computing device; and
in response to determining that the speech audio corresponding to the query was spoken by the user, generating a second audio signal that comprises the speech audio corresponding to the query and suppresses the played back audio from the first audio signal captured by the microphone.
|