| CPC G10L 15/183 (2013.01) [G06F 16/3329 (2019.01); G06F 16/3337 (2019.01); G06F 18/22 (2023.01); G06F 40/47 (2020.01); G06F 40/58 (2020.01); G06N 20/00 (2019.01); G10L 15/005 (2013.01); G10L 15/22 (2013.01); H04L 51/02 (2013.01)] | 10 Claims |
|
1. A method for training a neural machine translation model to translate from a first language to a second language, the method implemented by one or more processors and comprising:
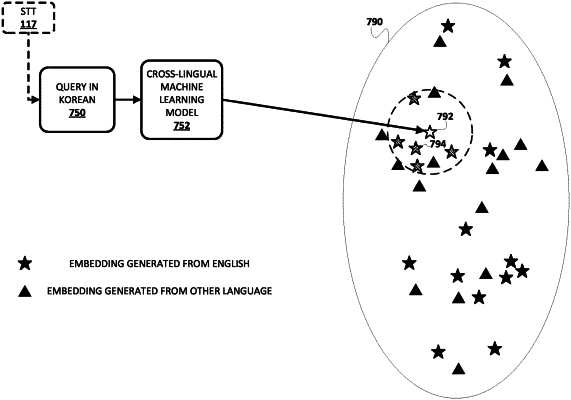
applying a multi-word textual query in the first language as input across a cross-lingual machine learning model that is different from the neural machine translation model to generate a first embedding of the multi-word textual query in a reduced dimensionality space;
identifying a plurality of additional embeddings in the reduced dimensionality space based on one or more respective proximities of the plurality of additional embeddings to the first embedding in the reduced dimensionality space, wherein the respective proximities are determined using cosine similarity or Euclidean distance, and the plurality of additional embeddings were generated based on a plurality of respective multi-word textual queries in the second language;
selecting one of the textual queries in the second language from the plurality of embeddings based on one or more additional criteria, wherein the one or more additional criteria include one or more of:
a shortest edit distance between the multi-word textual query in the first language and the selected one of the textual queries in the second language;
the multi-word textual query in the first language and the selected one of the textual queries in the second language being submitted to automated assistants at the most similar frequencies;
the most similar lengths of the multi-word textual query in the first language and the selected one of the textual queries in the second language; or
the multi-word textual query in the first language and the selected one of the textual queries in the second language having the most shared characters;
generating and storing at least one training example of the training data using the multi-word textual query in the first language and the selected one of the multi-word textual queries in the second language that was used to generate a respective one of the additional embeddings; and
training the neural machine translation model using the training data.
|