| CPC G06N 3/063 (2013.01) [G06N 3/08 (2013.01)] | 13 Claims |
|
1. A method for execution of a computational graph in a neural network model, characterized in that task execution bodies on a native machine are created according to a physical computational graph compiled and generated by a deep learning framework, and a plurality of idle memory blocks are allocated to each task execution body, so that the entire computational graph simultaneously participates in a deep learning training task in a pipelining and parallelizing manner, the method comprising the following steps:
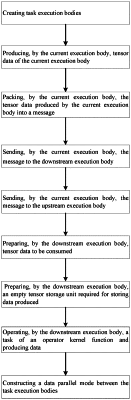
S1: creating the task execution bodies, wherein operator kernel functions for operating different operators are regarded as different computational tasks, and the task execution bodies are constructed respectively corresponding to respective kernel functions to execute the operator kernel functions; wherein the task execution bodies include a current execution body, a downstream execution body in communication with the current execution body, and an upstream execution body in communication with the current execution body;
S2: producing, by the current execution body, tensor data of the current execution body;
S3: packing, by the current execution body, the tensor data produced by the current execution body into a message;
S4: sending, by the current execution body, the message to the downstream execution body;
S5: sending, by the current execution body, the message to the upstream execution body;
S6: preparing, by the downstream execution body, the tensor data, wherein the downstream execution body prepares the tensor data according to the message sent from the current execution body;
S7: preparing, by the downstream execution body, an idle tensor memory block for storing the tensor data produced by the downstream execution body;
S8: performing, by the downstream execution body, a task of an internal operator kernel function of the downstream execution body, and producing output tensor data;
S9: constructing a data parallelizing mode between the task execution bodies, including the following specific sub-steps:
S91: allocating an idle memory block to each task execution body, wherein a specific process of step S91 is as follows:
S911: constructing a physical computational graph composed of a plurality of operators having production and consumption relationships, wherein the plurality of operators are labeled as operator a, operator b, operator c, . . . , and operator i; thus creating respective execution bodies for executing their own kernel functions respectively according to the operators, and constituting an execution computational graph composed of corresponding execution body A, execution body B, execution body C, . . . , and execution body I, which have production and consumption relationships;
S912: feeding different batches of input data and allocating a memory for tensor data produced when execution body A executes a kernel function of operator a, wherein the idle memory block corresponding to a zeroth batch of data is memory block a0, the idle memory block corresponding to a first batch of data is memory block a1, the idle memory block corresponding to a second batch of data is memory block a2, . . . , and the idle memory block corresponding to an ith batch of data is memory block ai;
allocating a memory for tensor data produced when execution body B executes a kernel function of operator b, wherein the idle memory block corresponding to the zeroth batch of data is memory block b0, the idle memory block corresponding to the first batch of data is memory block b1, the idle memory block corresponding to the second batch of data is memory block b2, . . . , and the idle memory block corresponding to the ith batch of data is memory block bi;
allocating a memory for tensor data produced when execution body C executes a kernel function of operator c, wherein the idle memory block corresponding to the zeroth batch of data is memory block c0, the idle memory block corresponding to the first batch of data is memory block c1, the idle memory block corresponding to the second batch of data is memory block c2, . . . , and the idle memory block corresponding to the ith batch of data is memory block ci;
repeating procedures of steps S911 and S912 until a memory is allocated for tensor data produced when execution body I executes a kernel function of operator i;
S92: initiating execution of a task execution body, wherein: at time T0, the zeroth batch of data is input, execution body A executes the kernel function of operator a and writes an output tensor of an execution result into idle memory block a0; downstream execution body B, downstream execution body C, . . . , and downstream execution body I are in a waiting state since there are no readable input tensor data; and
S93: operating the entire computational graph in parallel, wherein:
at time T1, execution body A informs execution body B of reading memory block a0 produced by execution body A; execution body B receives a message of reading memory block a0 produced by execution body A and checks whether there is an idle memory block available in memory region b produced by execution body B; if idle memory block b0 is available, execution body B executes a computational task of the kernel function of operator b, reads memory block a0 and writes the output tensor produced by the execution into memory block b0; at time T1, execution body A also checks whether execution body A has a writable idle memory block; if execution body A has the writable idle memory block, execution body A also inputs the first batch of data at time T1 and writes the execution result into idle memory block a1, so that execution body A and execution body B start to operate in parallel, and downstream execution body C, . . . and downstream execution body I still wait since there are no readable data;
at time T2, execution body B, after producing memory block b0, sends a message to a downstream consumer, i.e. execution body C, to inform execution body C of reading memory block b0 produced by execution body B; at time T2, a message is sent to an upstream producer, i.e. execution body A, to inform execution body A of a fact that execution body B has used memory block a0 of execution body A; at time T2, execution body A sends memory block a1 produced for training the first batch of input data to execution body B for a second time; execution body B checks to find that it has idle memory block b1, and thus starts to read memory block a1 and write into idle memory block b1; execution body C receives a message of reading memory block b0, and when finding idle memory block c0 available therein, starts execution of a computational task of the kernel function of operator c, reads memory block b0 and writes into memory block c0; execution body A receives a message of memory block a0 having been used and returned by execution body B, checks to find that all of consumers of execution body A have used memory block a0, then recovers memory block a0 and labels it as an idle block; at time T2, execution body A continues execution and writes into memory block a2;
at time T2, execution bodies A, B, and C all operate, for the deep learning training task, at time T2, memory block b0 and memory block c0 store the zeroth batch of data for training; memory block a1 and memory block b1 store the first batch of data for training; memory block a2 stores the second batch of data for training; and
all the execution bodies are operated in a pipeline parallel manner by step S93.
|