| CPC G10L 15/063 (2013.01) [G10L 15/16 (2013.01); G10L 15/22 (2013.01); G10L 19/032 (2013.01); G10L 2019/0002 (2013.01)] | 20 Claims |
|
12. An electronic device, comprising:
a memory and one or more processors;
wherein the memory is configured to store a computer program executable by the one or more processors; and
wherein the one or more processors are configured to execute the computer program in the memory to implement acts comprising:
for each of a plurality of training samples,
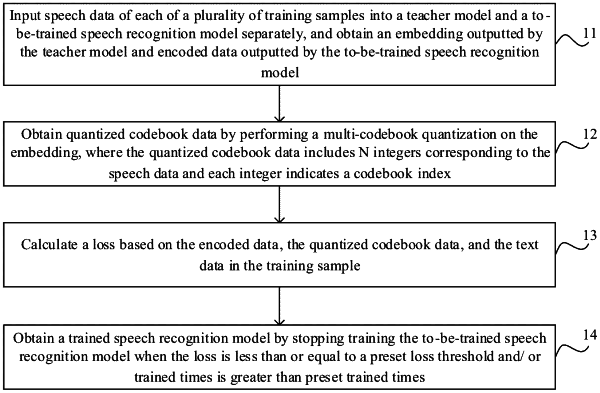
inputting speech data of a training sample into a teacher model and a to-be-trained speech recognition model separately,
obtaining an embedding outputted by the teacher model and encoded data outputted by the to-be-trained speech recognition model, wherein the embedding comprises a floating-point vector holding D floating-point numbers,
obtaining quantized codebook data by performing a multi-codebook quantization on the embedding, wherein the quantized codebook data comprises N integers corresponding to the speech data and each integer indicates a codebook index, wherein N is a positive integer,
calculating a loss based on the encoded data, the quantized codebook data, and text data in the training sample, and
obtaining a trained speech recognition model by stopping training the to-be-trained speech recognition model in response to determining at least one of followings: the loss being less than or equal to a preset loss threshold, or trained times being greater than preset trained times.
|