| CPC G06V 40/171 (2022.01) [G05D 1/60 (2024.01); G06T 7/10 (2017.01); G06T 7/50 (2017.01); G06T 7/75 (2017.01); G06V 10/26 (2022.01); G06V 10/80 (2022.01); G06V 10/82 (2022.01); G05D 2105/31 (2024.01); G05D 2111/10 (2024.01); G06T 2207/10024 (2013.01); G06T 2207/10028 (2013.01); G06T 2207/20081 (2013.01); G06T 2207/20084 (2013.01); G06T 2207/20221 (2013.01); G06T 2207/30201 (2013.01)] | 8 Claims |
|
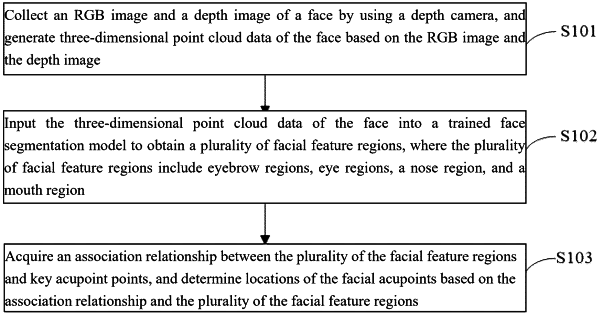
1. A facial acupoint locating method, comprising:
collecting an RGB image and a depth image of a face by using a depth camera, and generating three-dimensional point cloud data of the face based on the RGB image and the depth image;
inputting the three-dimensional point cloud data of the face into a trained face segmentation model to obtain a plurality of facial feature regions, wherein the plurality of the facial feature regions comprise eyebrow regions, eye regions, a nose region, and a mouth region; and
acquiring an association relationship between the plurality of the facial feature regions and key acupoint points, and determining locations of the facial acupoints based on the association relationship and the plurality of the facial feature regions;
wherein the face segmentation model comprises a feature extraction module, a channel attention module, a spacial attention module, and a segmentation module;
the feature extraction module comprises a first multi-layer perceptron, a second multi-layer perceptron, a third multi-layer perceptron, a fourth multi-layer perceptron, a fifth multi-layer perceptron, a maximum pooling layer, and a feature concatenation layer which are sequentially connected and share a weight; and
the inputting the three-dimensional point cloud data of the face into a trained face segmentation model to obtain a plurality of facial feature regions comprises:
inputting the three-dimensional point cloud data of the face into the feature extraction module to obtain facial features;
inputting the facial features into the channel attention module to obtain channel features;
inputting the channel features into the spacial attention module to obtain space-channel features; and
inputting the space-channel features into the segmentation module to obtain the plurality of the facial feature regions, wherein
each of the first multi-layer perceptron, the second multi-layer perceptron, the third multi-layer perceptron, the fourth multi-layer perceptron, and the fifth multi-layer perceptron comprises a convolutional layer, a batch normalization layer, and an activation function layer;
the first multi-layer perceptron is used for extracting features of a first scale of a three-dimensional point cloud of the face to obtain first-scale features;
the second multi-layer perceptron is used for extracting features of a second scale of the three-dimensional point cloud of the face to obtain second-scale features;
the third multi-layer perceptron is used for extracting features of a third scale of the three-dimensional point cloud of the face to obtain third-scale features;
the fourth multi-layer perceptron is used for extracting features of a fourth scale of the three-dimensional point cloud of the face to obtain fourth-scale features;
the fifth multi-layer perceptron is used for extracting features of a fifth scale of the three-dimensional point cloud of the face to obtain fifth-scale features;
the maximum pooling layer is used for performing maximum pooling on the fifth-scale features to obtain global features; and
the feature concatenation layer is used for concatenation the first-scale features, the second-scale features, the third-scale features, the fourth-scale features, the fifth-scale features, and the global features to obtain the facial features.
|