| CPC G06V 30/416 (2022.01) [G06F 16/2379 (2019.01); G06F 16/3344 (2019.01); G06F 16/34 (2019.01); G06F 16/382 (2019.01); G06F 16/901 (2019.01); G06F 16/9024 (2019.01); G06F 16/93 (2019.01); G06F 16/9558 (2019.01); G06F 40/205 (2020.01); G06V 30/412 (2022.01); G06V 30/413 (2022.01)] | 13 Claims |
|
1. A computing system comprising:
one or more processors; and
one or more computer-readable media having stored thereon computer-executable instructions that are structured such that, when executed by the one or more processors, cause the computing system to perform at least:
use hierarchical classification to classify a plurality of patent documents into a plurality of categories, wherein using hierarchical classification to classify the plurality of patent documents into the plurality of categories includes:
for each patent document of the plurality of patent documents, perform the following:
parse textual information of the patent document using a natural language processing (NLP) engine,
based upon the textual information of the patent document, extract a third set of features representing the textual information of the patent document,
transform the third set of features into a third feature vector, the third feature vector being a vector having a plurality of dimensions, each of which corresponds to a value of a feature contained in the third set of features,
use hierarchical classification to classify the plurality of third feature vectors corresponding to the plurality of patent documents into the plurality of categories, and
calculate a centroid of all the plurality of third feature vectors corresponding to all the plurality of patent documents within each category as a category feature vector for the corresponding category;
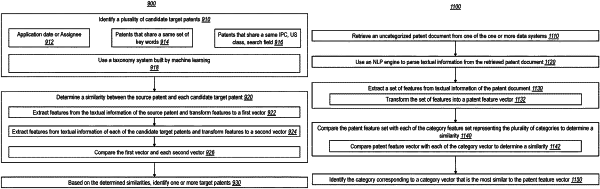
identify a first patent document in one or more first data systems, the first patent document not categorized in a machine-learning-generated taxonomy system;
retrieve the first patent document from the one or more first data systems;
use the NLP engine to parse textual information from the first patent document;
extract a fourth set of features of the first patent document from the textual information of the first patent document;
transform the fourth set of features into a fourth feature vector, the fourth feature vector being a vector having a plurality of dimensions, each of which corresponds to a value of a feature contained in the fourth set of features;
compare the fourth feature vector corresponding to the first patent document with each category feature vector to determine a similarity;
assign the first patent document to a category corresponding to a category feature vector that has a highest similarity to the fourth feature vector corresponding to the first patent document;
receive an input indicating a source patent, the source patent being a patent application or an issued patent published by the one or more first data systems;
retrieve a source patent document associated with the source patent from the one or more first data systems;
parse textual information of the source patent document using the NLP engine;
based upon the textual information of the source patent document, extract a first set of features that represent the textual information of the source patent document;
transform the first set of features to a first feature vector, the first feature vector being a vector having a plurality of dimensions, each of which corresponds to a value of a feature contained in the first set of features;
determine a similarity between the first feature vector corresponding to the source patent document and a particular category feature vector corresponding to a particular category, wherein the particular category feature vector comprises a particular centroid of all the plurality of third feature vectors corresponding to all the patent documents within the particular category;
identify a plurality of candidate patents within the particular category;
for each of the plurality of candidate patents, perform the following:
retrieve a candidate patent document from one of the one or more first data systems,
parse textual information of the candidate patent document using the NLP engine,
based upon the textual information of the candidate patent document, extract a second set of features representing the textual information of the candidate patent document,
transform the second set of features into a second feature vector, the second feature vector being a vector having a plurality of dimensions, each of which corresponds to a value of a feature contained in the second set of features, and
determine a similarity between the first feature vector corresponding to the source patent document and the second feature vector corresponding to the candidate patent document;
based on the similarities between the first feature vector and each second feature vector, identify one or more target patents; and
visualize the source patent and the one or more target patents.
|