| CPC G01V 11/002 (2013.01) | 4 Claims |
|
1. A sand shale formation lithology method for precise deep oil and gas navigation and drilling, comprising:
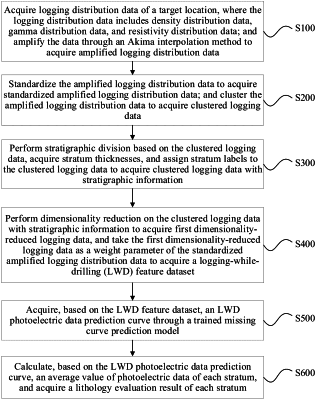
S100: acquiring logging distribution data of a target location, wherein the logging distribution data comprises density distribution data, gamma distribution data and resistivity distribution data, wherein the density distribution data, the gamma distribution data and the resistivity distribution data are represented as 8-sector data; and amplifying the density distribution data, the gamma distribution data and the resistivity distribution data of the target location through an Akima interpolation method to acquire amplified logging distribution data, wherein the amplified logging distribution data is represented as 32-sector data, comprising amplified density distribution data, amplified gamma distribution data, and amplified resistivity distribution data;
wherein the step of amplifying the density distribution data, the gamma distribution data and the resistivity distribution data of the target location through the Akima interpolation method to acquire the amplified logging distribution data comprises:
for any two adjacent data points xk and xk+1, (k=0, 1, 2, . . . , n):
acquiring a constraint condition for a fitted curve:
 wherein, yk denotes an actual logging value at xk; yk+1 denotes an actual logging value at xk+1; tk denotes a slope of the fitted curve at xk and xk+1; tk+1 denotes a slope at xk+1 and xk+2; S(xk) denotes a value of a cubic polynomial interpolation equation at xk; yk′ denotes a slope of the actual logging value at xk; and yk+1′ denotes a slope of the actual logging value at xk+1;
constructing the cubic polynomial interpolation equation:
S(x)=c0+c1(x−xk)+c2(x−xk)2+c3((x−xk)3;
wherein, S(x) denotes an interval function corresponding to an interval of [xk×k+1]; xk and xk+1 denote two adjacent data points; and c0, c1, c2, and c3 are constant parameters to be determined;
calculating an interpolation point for each interval based on the cubic polynomial interpolation equation;
calculating, based on the interpolation point, an interval interpolation equation through adjacent data points;
wherein, tk and tk+1 are expressed as follows:
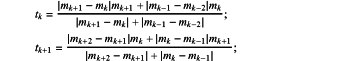 wherein, mk denotes the slope at the two data points xk and xk+1:
 mk+1 denotes a slope at two data points xk+1 and xk+2; mk−1 denotes a slope at two data points xk−1 and xk; mk−2 denotes a slope at two data points xk−2 and xk−1; mk+2 denotes a slope at two data points xk+2 and xk+3; and thus, the amplified logging distribution data are acquired;
S200: standardizing the amplified logging distribution data to acquire standardized amplified logging distribution data, wherein the standardized amplified logging distribution data comprises standardized amplified density distribution data, standardized amplified gamma distribution data, and standardized amplified resistivity distribution data; and clustering the amplified logging distribution data to acquire clustered logging data;
S300: performing stratigraphic division based on the clustered logging data, acquiring stratum thicknesses dstr, and assigning stratum labels to the clustered logging data to acquire clustered logging data with stratigraphic information;
S400: performing dimensionality reduction on the clustered logging data with stratigraphic information to acquire first dimensionality-reduced logging data, and taking the first dimensionality-reduced logging data as a weight parameter of the standardized amplified logging distribution data to acquire a logging-while-drilling (LWD) feature dataset;
S500: acquiring, based on the LWD feature dataset, an LWD photoelectric data prediction curve through a trained missing curve prediction model;
wherein, the LWD photoelectric data prediction curve is acquired through the trained missing curve prediction model as follows:
forming the missing curve prediction model, comprising a t-channel image recognition network with 2t convolutional layers and 2t average pooling layers, wherein each channel comprises a first convolutional layer, a first average pooling layer, a second convolutional layer and a second average pooling layer that are sequentially connected; each convolutional layer has a different size; an f-th channel comprises a (4×f−1)×(4×f−1) first convolutional layer, a (4×f+4)×(4×f+4) second convolutional layer, and 2×2 pooling layers; and all the channels are connected together to one fully connected layer and one naive Bayesian decision maker;
denoting the first convolutional layer of a first channel, the first convolutional layer of a second channel, and the first convolutional layer of a third channel as a C1 layer, a C3 layer, and a C5 layer, respectively, wherein the C1 layer is configured to convolve an input image through 8 ht×ht convolution kernels; the C3 layer is configured to convolve an input image through 8 3ht×3ht convolution kernels; and the C5 layer is configured to convolve an input image through 8 5ht×5 ht convolution kernels, wherein a convolution result is calculated as follows:
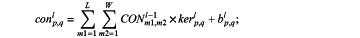 wherein, conp, ql denotes the convolution result at a position (p, q); l denotes a current layer number; CON denotes a matrix covered by the convolution kernels; L and W denote a length and a width of the matrix covered by the convolution kernels; m1 and m2 denote serial numbers of lengths of the convolution kernels, m1 ranging from 1 to L, and m2 ranging from 1 to W; ker denotes a kernel function; and b denotes a corresponding bias term;
fitting the convolution result through a rectified linear unit (ReLU) function to acquire a fitted convolution result;
performing upsampling pooling on the fitted convolution result:
conm3,m4l=max(CONm1,m2l-1);
wherein, conm3, m4l denotes a two-dimensional matrix representation of a pooled convolution result; and (m3, m4) denotes a position of the convolution result;
converting the pooled convolution result into a tiled one-dimensional feature vector through a tiling layer;
integrating the tiled one-dimensional feature vector through the fully connected layer:
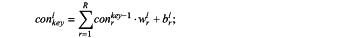 wherein, conkeyl denotes a one-dimensional matrix representation of a feature after the integration through the fully connected layer; l denotes the current layer number; key denotes an index value of a one-dimensional matrix; R denotes a length of a feature vector in an (l−1)-th layer; w denotes a weight matrix; b denotes the bias term; and r denotes a serial number of a data point of the feature vector;
introducing the naive Bayesian decision maker into the fully connected layer; and
taking the integrated tiled one-dimensional feature vector as the LWD photoelectric data prediction curve;
S600: calculating, based on the LWD photoelectric data prediction curve, an average value of photoelectric data of each stratum, and acquiring a lithology evaluation result of each stratum; and
S700: placing and drilling a well based on the average value of photoelectric data of each stratum and the lithology evaluation result of each stratum.
|