| CPC G06F 40/58 (2020.01) [G06F 40/51 (2020.01); G10L 15/005 (2013.01); G10L 15/22 (2013.01)] | 20 Claims |
|
1. A system to generate a voice-based interface, comprising:
a data processing system comprising a memory and one or more processors that execute a natural language processor component, a translation engine, and a signal generator component to:
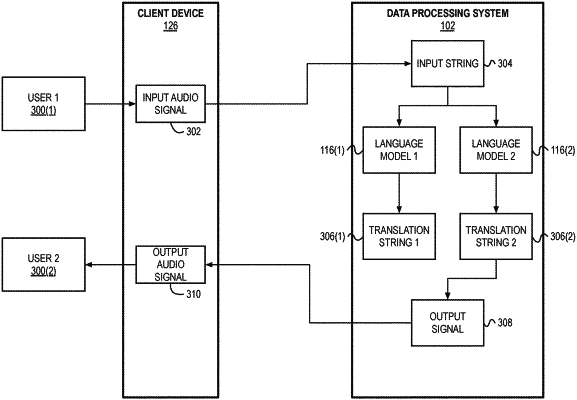
receive, at an interface of the data processing system, a first input audio signal detected by a sensor of a client device;
generate, based on the first input audio signal, a first translation string in a second language and a second translation string in a first language, wherein the first translation string in the second language is generated using a first language model having the first language as an input language, the second translation string in the first language is generated using a second language model having the second language as the input language, and the second language is different from the first language;
determine a first translation score based on a likelihood that the first input audio signal comprises an utterance in the first language and a second translation score based on a likelihood that the first input audio signal comprises an utterance in the second language;
select the first translation string based on the first translation score and the second translation score;
generate an output signal from the first translation string; and
transmit, by the interface, the output signal to the client device to render the output signal.
|