| CPC G06F 40/295 (2020.01) [G06F 40/106 (2020.01); G06F 40/30 (2020.01); G06N 3/08 (2013.01); G06T 11/60 (2013.01)] | 30 Claims |
|
1. A system comprising:
one or more processors of a machine; and
at least one memory storing instructions that, when executed by the one or more processors, cause the machine to perform operations comprising:
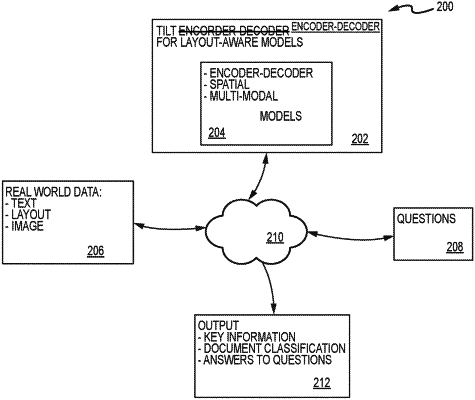
providing access to a cloud data platform including a machine learning model for performing a plurality of iterations to generate a Natural Language Processing (NLP) model, each iteration comprising:
receiving real-world documents;
enabling information retrieval from the real-world documents without annotated training data;
receiving data comprising text data, layout data, and image data;
analyzing the text data, the layout data, and the image data; and
generating one or more outputs from the machine learning model by applying the plurality of iterations on new data, based at least in part on the analyzing of the text data, the layout data, and the image data.
|