| CPC H04R 25/505 (2013.01) [G06F 3/165 (2013.01); G10H 1/361 (2013.01); G10L 25/18 (2013.01); H04R 25/353 (2013.01); H04R 25/356 (2013.01); H04R 25/43 (2013.01); H04R 25/558 (2013.01); G10H 2210/005 (2013.01); H04R 25/554 (2013.01); H04R 2225/025 (2013.01); H04R 2225/55 (2013.01)] | 14 Claims |
|
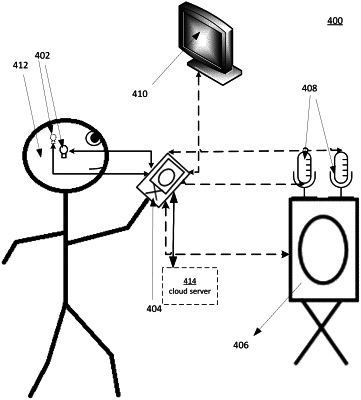
1. A computer-implemented method for selectively tuning audio output to an earpiece worn by a user, comprising:
executing, by at least one processor, a display routine to display a graphical user interface to the user on a screen connected to the at least one processor, and further displaying by the at least one processor a menu comprising a plurality of tuning profiles for the user for selecting a tuning profile within the graphical user interface;
obtaining input from the user, based on the user's interaction with the graphical user interface, said input comprising a chosen tuning profile and sensory input from the user, wherein the sensory input from the user is in the form of raw data which may be stored by the at least one processor in a local repository in a primary or secondary memory associated with said at least one processor;
processing, by the at least one processor, an input audio signal from the earpiece or an external microphone;
receiving the input signal and storing the input signal in the local repository, by the at least one processor;
transforming the input audio signal from a time domain to a frequency domain using a Fourier transform by the at least one processor;
altering the input signal in the frequency domain, amplifying the input signal according to the chosen tuning profile for output to the earpiece or an externally connected speaker, by the at least one processor;
performing an inverse Fourier transform on the altered audio signal according to the tuning chosen by the user to obtain an altered audio signal to be output to the earpiece worn by the user or an externally connected speaker in the time domain, by the at least one processor; and
transmitting the altered audio signal in the time domain to the earpiece worn by the user or an externally connected speaker by the at least one processor or both, wherein the earpiece has no custom-molded in-ear components.
|