| CPC G10L 17/04 (2013.01) [G06F 21/32 (2013.01); G10L 17/24 (2013.01)] | 17 Claims |
|
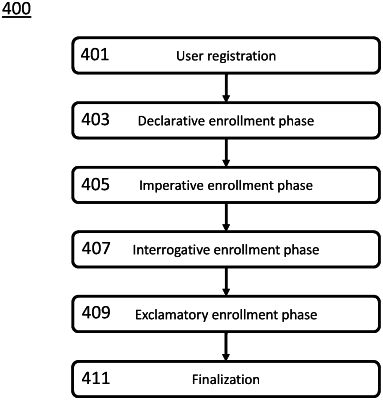
1. A method for enrolling a user in a multi-stage enrollment voice authentication or identification system, comprising:
capturing a plurality of speech samples of the user's speech to obtain user speech samples';
categorizing the plurality of speech samples into the following sentence types: (1) a declarative sentence; (2) an imperative sentence; (3) an interrogative sentence; (4) an exclamatory sentence;
computing feature-space representations for each of the sentence types, wherein a boundary is determined for the feature-space representations for each of the sentence types;
generating a user enrollment voiceprint by aggregating the feature-space representations, wherein the aggregated feature-space representations include at least two different sentence types, wherein the aggregated feature-space representations have a modified boundary;
associating the user enrollment voiceprint with user information; and
storing the user enrollment voiceprint and associated user information in a database of enrolled users.
|