| CPC G10L 13/10 (2013.01) [G06N 3/08 (2013.01); G06N 20/00 (2019.01); G10L 13/027 (2013.01); G10L 13/04 (2013.01)] | 13 Claims |
|
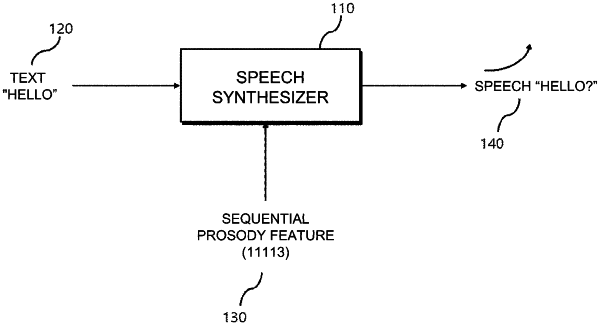
1. A text-to-speech synthesis method using machine learning based on a sequential prosody feature, comprising:
receiving an input text;
receiving a sequential prosody feature; and
generate output speech data for the input text reflecting the received sequential prosody feature by inputting the input text and the received sequential prosody feature to an artificial neural network text-to-speech synthesis model,
wherein receiving the sequential prosody feature includes receiving a plurality of embedding vectors representing the sequential prosody feature,
wherein the artificial neural network text-to-speech synthesis model includes an encoder and a decoder,
wherein the method further includes inputting the received plurality of embedding vectors to an attention module to generate a plurality of converted embedding vectors corresponding to respective parts of the input text provided to the encoder, wherein lengths of the plurality of converted embedding vectors varies with a length of the input text, and
wherein generating the output speech data for the input text includes:
inputting the generated plurality of converted embedding vectors to the encoder of the artificial neural network text-to-speech synthesis model, and
generating output speech data for the input text reflecting the plurality of converted embedding vectors.
|