| CPC G10L 13/033 (2013.01) [G10L 13/047 (2013.01)] | 19 Claims |
|
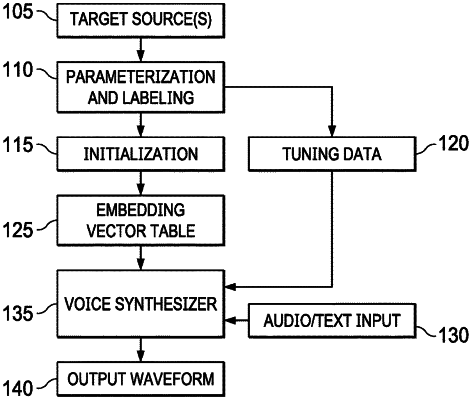
1. A method to synthesize a voice in a target style, comprising:
receiving as input at least one waveform, each corresponding to an utterance in the target style;
extracting features on the at least one waveform and generating at least one embedding vector from the extracted features;
calculating vector distances on an embedding vector of the at least one embedding vector to determine embedding vector distances to each of a plurality of known embedding vectors;
determining a known embedding vector of the known embedding vectors with a shortest distance from the embedding vector;
designating the known embedding vector as an initial embedding vector for a speech synthesizer;
adapting the speech synthesizer based on the initial embedding vector; and synthesizing a voice in the target style with the adapted speech synthesizer.
|