| CPC G06T 13/40 (2013.01) [G06T 13/205 (2013.01); G06T 13/80 (2013.01); G06V 10/774 (2022.01); G06V 10/82 (2022.01); G06V 10/98 (2022.01); G06V 40/20 (2022.01); G10L 21/06 (2013.01)] | 9 Claims |
|
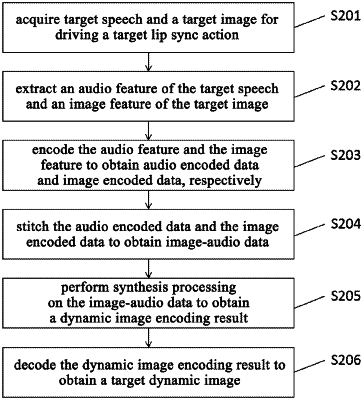
1. A system model on cloud for audio-driven character lip sync, wherein the model on cloud is configured to:
extract an audio feature of target speech and an image feature of a target image, wherein the target speech indicates speech for a target dynamic image generated for a target character, the target image indicates a lip sync image for the target dynamic image generated for the target character, and the target dynamic image indicates a video image when the target image performs lip sync actions corresponding to the target speech;
encode the audio feature and the image feature to obtain audio encoded data and image encoded data, respectively;
stitch the audio encoded data and the image encoded data to obtain image-audio data;
perform synthesis processing on the image-audio data to obtain a dynamic image encoding result;
decode the dynamic image encoding result to obtain the target dynamic image; and
generate, during a training process of the model, a silent video with preset duration based on a sample image, process the silent video as sample image data, and process an auxiliary video as auxiliary data, wherein the sample image indicates a lip sync image of the target character; the auxiliary video comprises a non-target lip sync action generated through speaking by a non-target character and non-target speech corresponding to the non-target lip sync action; and the sample image data and the auxiliary data are used for training of the model.
|