| CPC G06N 3/04 (2013.01) [G06F 17/15 (2013.01); G06N 3/044 (2023.01); G06N 3/084 (2013.01); G06N 20/10 (2019.01); G06N 3/045 (2023.01)] | 20 Claims |
|
1. A computing system, comprising:
one or more processors; and
one or more non-transitory computer-readable media that store:
a machine-learned convolutional neural network; and
instructions that, when executed by the one or more processors, cause the computing system to employ the machine-learned convolutional neural network to process input image data to output an inference;
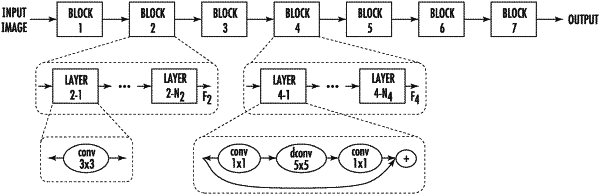
wherein the machine-learned convolutional neural network comprises a plurality of convolutional blocks arranged in a sequence one after the other;
wherein the plurality of convolutional blocks comprise two or more convolutional blocks that each perform an inverted bottleneck convolution to produce an output; and
wherein at least two of the two or more convolutional blocks apply convolutional kernels that have different respective kernel sizes to respectively perform the inverted bottleneck convolution.
|