| CPC G06N 20/00 (2019.01) [G06N 5/04 (2013.01)] | 20 Claims |
|
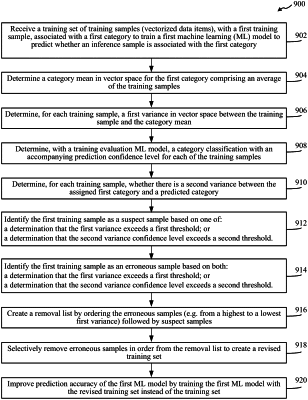
1. A method, comprising:
receiving a training set comprising training samples associated with a first category to train a first machine learning (ML) model;
generating a category score for the first category based on a total variance of the training samples associated with the first category;
identifying the first category as a suspect category subject to removal in response to the category score indicating excessive variance of the training samples associated with the first category relative to a threshold variance score; and
improving prediction accuracy of the first ML model by revising the training set by at least one of
refining the training samples associated with the first category, or
eliminating the training samples of the first category from the training set.
|