| CPC G06F 40/30 (2020.01) [G06F 18/2113 (2023.01); G06F 18/213 (2023.01); G06F 18/2163 (2023.01); G06F 18/253 (2023.01); G06F 40/284 (2020.01)] | 7 Claims |
|
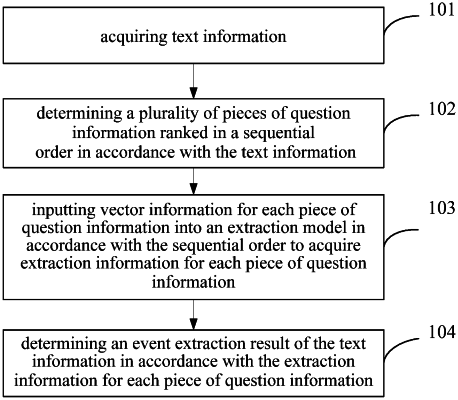
1. An event extraction method, comprising:
acquiring text information;
determining a plurality of pieces of question information ranked in a sequential order in accordance with the text information;
inputting vector information for each piece of question information into an extraction model in accordance with the sequential order to acquire extraction information for each piece of question information, the vector information comprising an answer mark vector; and
determining an event extraction result of the text information in accordance with the extraction information for each piece of question information;
wherein the vector information further comprises a position vector,
wherein subsequent to determining the plurality of pieces of question information ranked in a sequential order in accordance with the text information, and prior to inputting the vector information for each piece of question information into the extraction model in accordance with the sequential order to acquire the extraction information for each piece of question information, the event extraction method further comprises:
performing word segmentation on each piece of question information to acquire at least one target word;
acquiring a position vector of each of the at least one target word; and
determining a position vector of the question information in accordance with the position vector of each of the at least one target word;
wherein the acquiring the position vector of each of the at least one target word comprises:
when the quantity of entities comprised in the question information is greater than or equal to M and the quantity of verbs comprised in the question information is greater than or equal to N, acquiring M entities and N verbs in the question information, M and N being each a positive integer;
calculating M first relative positions of each of the at least one target word relative to the M entities and N second relative positions of each of the at least one target word relative to the N verbs;
mapping the M first relative positions and the N second relative positions to normally-distributed vectors with predetermined dimensions, to acquire M first position vectors and N second position vectors;
splicing the M first position vectors in accordance with a sequential order of the M entities in the question information to acquire a first spliced vector;
splicing the N second position vectors in accordance with a sequential order of the N verbs in the question information to acquire a second spliced vector; and
splicing the first spliced vector with the second spliced vector and taking a splicing result as the position vector of the target word;
wherein the acquiring the M entities and the N verbs in the question information when the quantity of entities comprised in the question information is greater than or equal to M and the quantity of verbs comprised in the question information is greater than or equal to N comprises:
when the quantity of entities comprised in the question information is greater than M and the quantity of verbs comprised in the question information is greater than or equal to N, or when the quantity of verbs comprised in the question information is greater than N and the quantity of entities comprised in the question information is greater than or equal to M, performing syntax dependency analysis on the question information to acquire a plurality of dependency pairs;
selecting entities and verbs comprised in a same dependency pair in the plurality of dependency pairs to acquire m entities and n verbs, m and n being each a positive integer;
when m is smaller than M, selecting i entities from the entities in the question information other than the m entities to obtain the i entities, i being a difference between M and m; and
when n is smaller than N, selecting j verbs from the verbs in the question information other than the n verbs to obtain the j verbs, j being a difference between N and n.
|