| CPC G06F 16/27 (2019.01) | 20 Claims |
|
1. A system for maintaining a meta-database representing data from a plurality of source databases, the system comprising:
a computer including one or more processor and at least one of a memory device and a non-transitory storage device, wherein the one or more processor executes:
a source programing interface configured for interfacing with the plurality of source databases, the plurality of source databases including data associated with a plurality of variables, wherein a decentralized storage of the data results in inefficient selection of at least one of data or variables for modeling;
a meta-database programming interface configured for interfacing with the meta-database;
a key variable repository module configured to operably couple the plurality of source databases and the meta-database, the key variable repository module including an artificial intelligence program comprising:
a scanner algorithm configured to perform steps including:
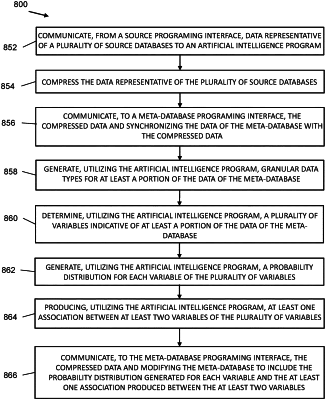
communicate with the source programing interface to receive the data of the source databases;
compress the data of the source databases;
communicate with the meta-database programing interface and synchronize the meta-database with the compressed data of the source databases;
a profiler algorithm configured to perform steps including:
communicate with the meta-database programing interface to receive the data of the meta-database;
generate, based on the data of the meta-database, granular data types for at least a portion of the data of the meta-database;
determine a plurality of variables indicative of at least a portion of the data of the meta-database and generate, for each variable, a probability distribution;
produce at least one association between at least two variables of the plurality of variables; and
communicate with the meta-database programing interface to modify the meta-database to include the probability distribution generated for each variable and the at least one association produced between the at least two variables; and
a key interface configured to allow searching the meta-database for at least one of a variable, a probability distribution for a variable, or a produced association between variables, wherein at least one of the meta-database or the key interface improves the efficiency in the selection of at least one of data or variables for modeling.
|