| CPC G06F 16/24556 (2019.01) [G06F 16/2228 (2019.01); G06F 16/283 (2019.01)] | 5 Claims |
|
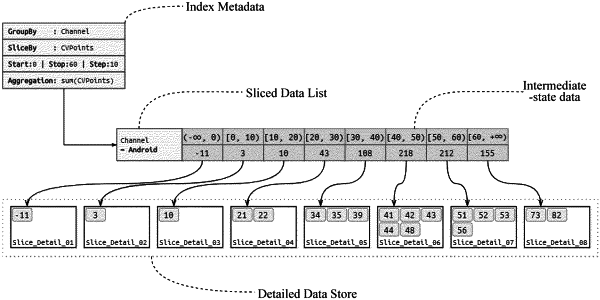
1. A data index apparatus for improving aggregation query efficiency, the apparatus comprising a memory and at least one processor, data to be analyzed being arranged in a structure of an aggregation index, wherein the aggregation index partitions streaming data by two dimensions of grouping and slicing, and then aggregates partitioned data, of which the structure comprises index metadata, a sliced data list and a detailed data store, wherein data arrangement, partition and aggregation are performed by the at least one processor according to instructions stored in the memory;
the index metadata contain definition information of the aggregation index, comprising a grouping field GroupBy, a slice field SliceBy, a slice starting point Start, a slice ending point Stop, a slice step length Step, an aggregation field and an aggregation function Aggregation;
the sliced data list consists of intermediate-state data of all slices belonging to a same group; the intermediate-state data of each slice contains a current slice range and an aggregation result; in addition, the intermediate-state data of each slice further contains a storage location of the detailed data corresponding to the slice, so as to implement more accurate query and operations of adding new data later;
the detailed data store stores the streaming detailed data in units of slices; the memory, a local file system or a distributed file system including Hadoop Distributed File System HDFS is selected as a storage medium of streaming detailed data according to different data volumes; the streaming detailed data store stores a value of the aggregation field or all fields of streaming details.
|