| CPC H04M 3/002 (2013.01) [G10L 21/0232 (2013.01); G10L 21/034 (2013.01); G10L 25/18 (2013.01); H04S 3/008 (2013.01); G10L 2021/02082 (2013.01); H04S 2400/01 (2013.01); H04S 2400/03 (2013.01)] | 20 Claims |
|
1. A system, comprising:
at least one processor; and
a memory, storing program instructions that when executed by the at least one processor, cause the at least one processor to implement an audio enhancement system, configured to:
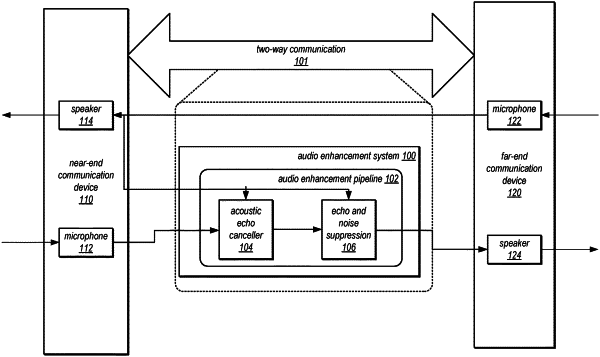
receive, via an interface for the audio enhancement system, first audio data captured by a microphone at a first communication device as part of a two-way audio communication between the first communication device and a second communication device;
receive second audio data transmitted from the second communication device to the first communication device for playback through a speaker at the first communication device as part of the two-way audio communication;
apply a machine learning model trained to determine respective gain values for a plurality of different spectrum bands of the first audio data to suppress noise and suppress echo captured in the first audio data from playback of the second audio data through a speaker at the first communication device, wherein the machine learning model accepts respective input features extracted from the second audio data as a reference signal and extracted from the first audio data based on respective representations of the second audio data and the first audio data in respective sets of frequency bands; and
apply an envelope post-filter that individually modifies the respective gain values according to a monotonically increasing function applied to the respective gain values;
perform an inverse transform on the plurality of different spectrum bands with the respectively modified gain values to generate an enhanced version of the first audio data; and
send the enhanced version of the first audio data to the second communication device for playback at the second communication device.
|