| CPC G10L 15/26 (2013.01) [G06F 40/205 (2020.01); G06F 40/284 (2020.01); G06F 40/30 (2020.01); G10L 15/1815 (2013.01); G10L 15/183 (2013.01); G10L 15/22 (2013.01); G10L 15/30 (2013.01); G10L 2015/223 (2013.01); G10L 2015/228 (2013.01)] | 17 Claims |
|
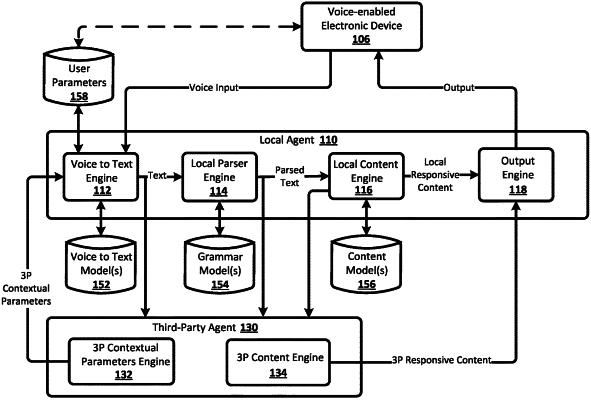
1. A method implemented by one or more processors, the method comprising:
receiving, by a third-party agent, and from a local agent that is local to a voice-enabled electronic device of a user, an invocation request for content;
in response to receiving the invocation request for the content, generating, by the third-party agent, responsive content that is responsive to voice input, provided by the user of the voice-enabled electronic device, that is directed to the local agent, and that is to be provided by the local agent in response to the voice input via the voice-enabled electronic device;
identifying, by the third-party agent, one or more contextual parameters that are in addition to the responsive content and that are indicative of further voice input, anticipated to be provided by the user of the voice-enabled electronic device, in response to the responsive content being output for presentation to the user via the voice-enabled electronic device; and
transmitting, by the third-party agent, and to the local agent, the responsive content and the one or more contextual parameters, wherein transmitting the responsive content and the one or more contextual parameters to the local agent cause to the local agent to:
output, for presentation to the user via the voice-enabled electronic device, the responsive content in response to the voice input;
receive, via the voice-enabled electronic device, an additional voice input provided by the user and in response to the output being provided for presentation to the user;
determine, via the voice-enabled electronic device, text to transmit to the third-party agent, wherein text is based on a voice to text conversion of the additional voice input and is based on one or more of the contextual parameters; and
transmit the text to the third-party agent.
|