| CPC G10L 15/197 (2013.01) [G10L 15/02 (2013.01); G10L 15/063 (2013.01); G10L 15/16 (2013.01); G10L 15/22 (2013.01); G10L 2015/025 (2013.01)] | 20 Claims |
|
1. A computer-implemented method executed on data processing hardware that causes the data processing hardware to perform operations comprising:
receiving a sequence of feature vectors indicative of acoustic characteristics of a training utterance;
receiving a ground-truth label sequence corresponding to the training utterance; and
training a speech recognition model to minimize word error rate by performing operations comprising:
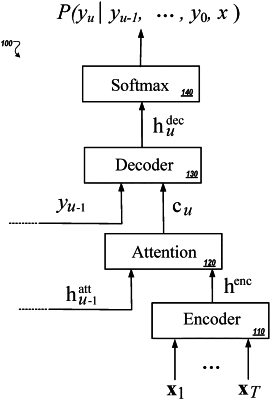
processing, using the speech recognition model, the sequence of feature vectors to obtain a set of speech recognition hypothesis samples for the training utterance in a beam search;
for each speech recognition hypothesis sample in the set of speech recognition hypothesis samples, identifying a respective number of word errors relative to the ground-truth label sequence corresponding to the training utterance; and
approximating a loss function based on a combination of the respective numbers of word errors identified for each speech recognition hypothesis sample in the set of speech recognition hypothesis samples.
|