| CPC G06T 11/60 (2013.01) [G06F 40/284 (2020.01); G06F 40/30 (2020.01); G06N 3/045 (2023.01); G06N 3/08 (2013.01); G06T 9/002 (2013.01); G06T 11/001 (2013.01)] | 20 Claims |
|
1. A system comprising:
at least one memory storing instructions;
at least one processor configured to execute the instructions to perform operations for generating an image corresponding to a text input, the operations comprising:
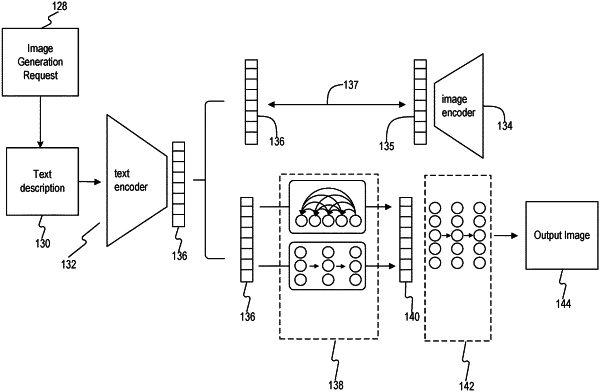
accessing a text description and inputting the text description into a text encoder;
receiving, from the text encoder, a text embedding;
inputting at least one of the text description or the text embedding into a first sub-model configured to generate, based on at least one of the text description or the text embedding, a corresponding image embedding;
inputting at least one of the text description or the corresponding image embedding, generated by the first sub-model, into a second sub-model configured to generate, based on at least one of the text description or the corresponding image embedding, an output image; wherein the second sub-model includes a first upsampler model and a second upsampler model configured for upsampling prior to generating the output image, the second upsampler model trained on images corrupted with blind super resolution (BSR) degradation; wherein the second sub-model is different than the first sub-model; and
making the output image, generated by the second sub-model, accessible to a device, wherein the device is at least one of:
configured to train an image generation model using the output image; or
associated with an image generation request.
|