| CPC G06N 3/08 (2013.01) [G06F 40/35 (2020.01); G06N 3/006 (2013.01); G06N 3/04 (2013.01)] | 20 Claims |
|
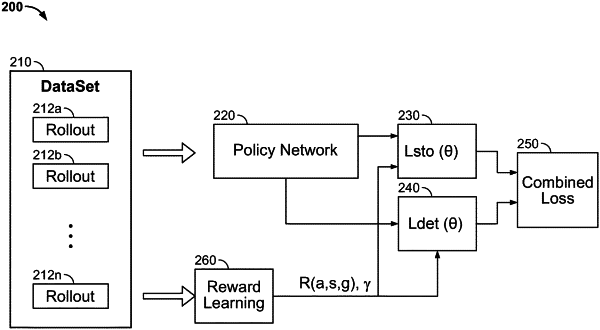
1. A method for policy improvement in task-oriented learning, the method comprising:
receiving a training dataset comprising a plurality of dialogue rollouts generated by a latent stochastic behavior policy, wherein each rollout includes a time series of observations representing information of a respective dialogue at a plurality of dialogue turns;
generating, by a neural model, a first predicted action distribution based on a current state of the respective dialogue according to a target policy;
computing a first discounted sum of future reward based on a discount parameter and a reward function of actions and states of the respective dialogue according to the latent behavior policy;
computing a first loss objective based on a first expectation of the first discounted sum of future reward and the first predicted action distribution, wherein the first expectation is taken over a probability distribution of the states and the actions according to the latent stochastic behavior policy; and
updating the neural model by minimizing at least the first loss objective subject to a condition that a KL-divergence between the latent stochastic behavior policy and the target policy conditioned on the current state of the respective dialogue is less than a pre-defined hyperparameter.
|