| CPC G06N 20/10 (2019.01) [G06F 16/2455 (2019.01); G06F 40/284 (2020.01)] | 22 Claims |
|
1. A method, comprising:
receiving a batch of two or more token sequences, wherein a length of a first token sequence in the batch is different from a length of a second token sequence in the batch;
accessing a transformer model;
generating one or more output representations, the generating further comprising:
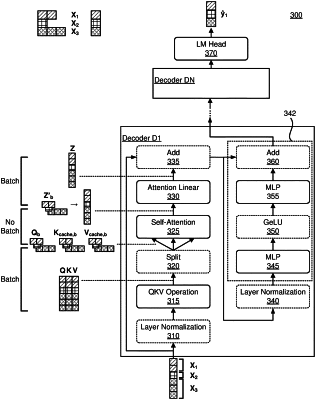
generating one or more queries, one or more keys, and one or more values for the batch by applying a QKV weight tensor to one or more input representations, the one or more queries, the one or more keys, and the one or more values generated by a batch operation,
splitting a first query for the first token sequence from the one or more queries, a first key from the one or more keys, and a first value from the one or more values, and splitting a second query for the second token sequence from the one or more queries, a second key from the one or more keys, and a second value from the one or more values,
generating a first attention output by at least combining the first query, the first key, and the first value,
separately generating a second attention output by at least combining the second query, the second key, and the second value, wherein the second attention output is generated at a different execution engine, a different hardware accelerator, a different graphics processor unit (GPU) kernel, or a same GPU kernel than the first attention output,
concatenating at least the first attention output and the second attention output into a concatenated tensor, and
generating one or more output representations by at least applying one or more weight tensors to the concatenated tensor, the one or more output representations generated by a batch operation.
|