| CPC G06F 18/2155 (2023.01) [G06F 18/10 (2023.01); G06F 18/2113 (2023.01); G06F 18/2115 (2023.01); G06F 18/213 (2023.01); G06F 18/22 (2023.01); G06F 18/23 (2023.01); G06F 18/2321 (2023.01); G06F 18/24137 (2023.01); G06F 18/2431 (2023.01); G06F 18/28 (2023.01); G06N 3/09 (2023.01); G06N 5/01 (2023.01); G06N 20/00 (2019.01); G06N 3/092 (2023.01)] | 18 Claims |
|
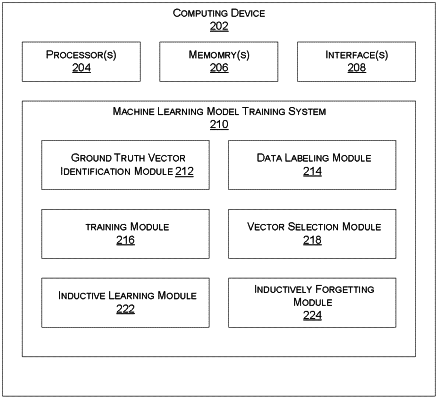
8. A system comprising:
a processing resource; and
a non-transitory computer-readable medium, coupled to the processing resource, having stored therein instructions that when executed by the processing resource cause the processing resource to:
receive a first set of feature vectors, wherein the first set of feature vectors are un-labeled;
group the first set of feature vectors into a plurality of clusters within a vector space having fewer dimensions than the first set of feature vectors by applying a homomorphic dimensionality reduction algorithm to the first set of feature vectors and performing centroid-based clustering;
identify an optimal set of clusters among the plurality of clusters by performing a convex optimization process on the plurality of clusters;
minimize vector labeling by selecting a plurality of ground truth representative vectors including a representative vector from each cluster of the optimal set of clusters;
create a set of labeled feature vectors based on labels received from an oracle for each of the plurality of representative vectors;
train a machine-learning model for multiclass classification based on the set of labeled feature vectors; and
train the machine-learning model with inductive learning, wherein the inductive learning comprises:
selecting an unlabeled feature vector from the first set of feature vectors;
classifying the un-labeled feature vector using the machine learning model to get a model classified cluster with a confidence score;
determining whether the confidence score is greater than a threshold; and
when said determining is affirmative:
determining a Mahalanobis distance of the un-labeled feature vector with respect to each labeled feature vector of the first set of feature vectors;
determining a statistically matching cluster of labeled feature vectors to which the un-labeled feature vector is closest based on the determined Mahalanobis distance;
determining whether the model classified cluster and the statistically matching cluster are the same; and
when the model classified cluster and the statistically matching cluster are determined to be the same:
labeling the un-labeled feature vector based on the label associated with the model classified cluster; and
model fitting the machine learning model based on the labeling.
|