| CPC G06F 16/358 (2019.01) [G06F 18/23213 (2023.01); G06F 40/289 (2020.01); G06F 40/30 (2020.01); G06N 3/02 (2013.01); G06N 20/00 (2019.01)] | 20 Claims |
|
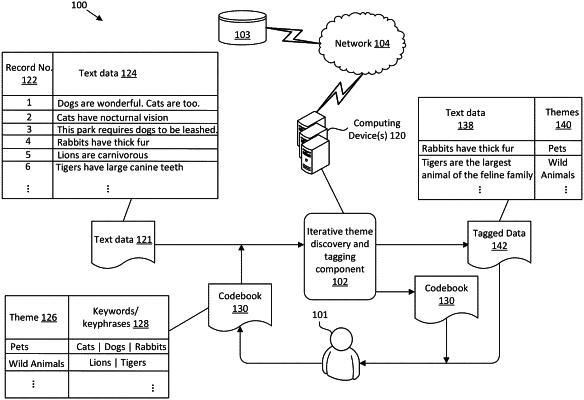
1. A method of discovering topics for text data, comprising:
receiving an input corpus of text data comprising a plurality of documents;
generating a codebook comprising a first number of topics, wherein each topic of the first number of topics is associated by the codebook with a corresponding set of keywords;
determining, for a first topic of the first number of topics, an average embedding of keywords associated with the first topic;
determining a distance in an embedding space between an embedding for a first document of the plurality of documents and the average embedding;
tagging the first document as pertaining to the first topic based at least in part on the distance;
receiving, from a first user, at least one edit to the codebook comprising at least one of adding a keyword, deleting a keyword, modifying a keyword, or re-naming a topic;
generating a modified codebook incorporating the at least one edit to the codebook;
inputting the modified codebook into a teacher model of a student-teacher machine learning model framework;
generating by a student model of the student-teacher machine learning model framework a probability that a second document corresponds to a second topic of the modified codebook; and
tagging the second document as pertaining to the second topic based at least in part on the probability.
|
|
4. A method comprising:
receiving, by at least one computing device, first text data separated into a plurality of documents;
identifying, by the at least one computing device, a codebook comprising a first topic associated with a first set of keywords;
tagging a first document of the plurality of documents with the first topic based at least in part on the first set of keywords of the codebook;
receiving instructions to modify the codebook to generate a modified codebook, wherein the instructions are effective to add to, delete from, and/or modify at least one of the first set of keywords or the first topic;
tagging the first document of the plurality of documents with the first topic based at least in part on the first set of keywords of the modified codebook; and
generating output data indicating that the first document pertains to the first topic.
|