| CPC G06F 16/285 (2019.01) [G06F 7/08 (2013.01); G06N 5/04 (2013.01); G06N 20/00 (2019.01)] | 18 Claims |
|
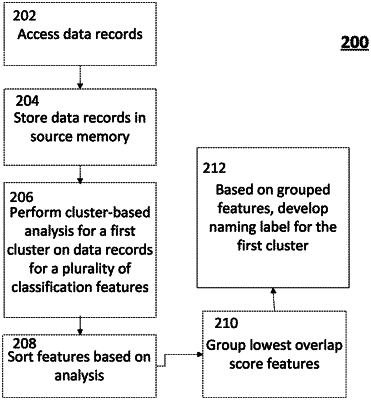
1. A computer-implemented method, comprising:
retrieving, by at least one computer processor, a plurality of data records from a database, wherein the plurality of data records have been categorized by an unsupervised machine-learning algorithm, and wherein each data record of the plurality of data records has been designated a cluster number out of a total K number of clusters;
for each of a plurality of classification features, performing, by the at least one computer processor, a cluster-based analysis for a first cluster in the K number of clusters to determine proximity of data records between different clusters and overlap with the first cluster, with respect to a single feature, the cluster-based analysis comprising:
determining, by the at least one computer processor, an average and standard deviation, collectively, for all data records forming the first cluster, for the single feature; and
determining, by the at least one computer processor, an average for all data records in each other cluster in the K number of clusters, for the single feature;
generating, by the at least one computer processor, based on the cluster-based analysis, a single feature overlap score for each of the plurality of classification features based on a proximity of the first cluster to the other clusters in the K number of clusters and an amount of overlap of the first cluster with the other clusters in the K number of clusters; and
generating, by the at least one computer processor, a naming label for the first cluster based on a predetermined number of features having lowest overlap scores of the plurality of classification features.
|