| CPC G06F 16/211 (2019.01) [G06F 16/2264 (2019.01); G06F 16/2282 (2019.01); G06F 16/25 (2019.01); G06F 16/285 (2019.01); G06N 5/04 (2013.01); G06N 20/00 (2019.01); G06N 20/20 (2019.01)] | 17 Claims |
|
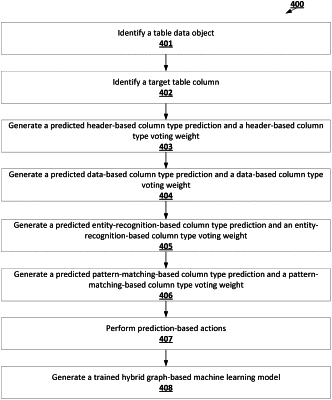
15. One or more non-transitory computer-readable storage media including instructions that, when executed by one or more processors, cause the one or more processors to:
identify a reference table data object associated with a table data object, wherein (i) the table data object comprises a plurality of table columns and (ii) the reference table data object comprises a plurality of reference table columns;
extract a reference table column feature of a plurality of reference table column features for each of the plurality of reference table columns, wherein at least one reference table column feature of the plurality of reference table column features comprises a sparsity feature of the corresponding reference table column;
for each table column pair that comprises a table column of the table data object and a reference table column of the reference table data object, determine a table column pair similarity measure based at least in part on a table column mapping and a reference table column mapping, wherein: (i) the reference table column mapping maps the corresponding reference table column to a multi-dimensional clustering space based at least in part on a defined set of table column features and (ii) the defined set of table column features comprises at least a sparsity feature of the corresponding table column;
determine, based at least in part on each table column pair similarity measure, a variance report for the table data object, wherein the variance report describes at least one table column that does not achieve a similarity threshold associated with its table column pair; and
initiate the performance of one or more prediction-based actions based at least in part on the variance report.
|