| CPC H04R 5/04 (2013.01) [G02B 27/0172 (2013.01); G10L 15/08 (2013.01); H04R 3/005 (2013.01); H04R 3/04 (2013.01); H04R 5/033 (2013.01); G06T 19/006 (2013.01)] | 21 Claims |
|
1. A system comprising:
a first microphone;
a second microphone;
a head-wearable device configured to be worn by a user, the head-wearable device comprising a glasses frame comprising the first microphone and the second microphone; and
one or more processors configured to perform a method comprising:
receiving, via the first microphone, a first microphone output based on an audio signal, the audio signal provided by the user;
receiving, via the second microphone, a second microphone output based on the audio signal;
determining, via a first processor of the one or more processors, whether the audio signal comprises a voice onset event;
in accordance with a determination that the audio signal comprises the voice onset event:
waking a second processor of the one or more processors;
determining, via the second processor of the one or more processors, whether the audio signal comprises a predetermined trigger signal;
in accordance with a determination that the audio signal comprises the predetermined trigger signal:
waking a third processor of the one or more processors;
performing, via the third processor of the one or more processors, automatic speech recognition based on the audio signal; and
in accordance with a determination that the audio signal does not comprise the predetermined trigger signal:
forgoing waking the third processor of the one or more processors; and
in accordance with a determination that the audio signal does not comprise the voice onset event:
forgoing waking the second processor of the one or more processors, wherein:
the first microphone is disposed in a first region of the glasses frame;
the second microphone is disposed in a second region of the glasses frame;
the glasses frame further comprises a left eye portion comprising the first region;
the glasses frame further comprises a right eye portion comprising the second region;
the first region is configured to rest at a first height with respect to the user's mouth when the head-wearable device is worn by the user;
the second region is configured to rest at a second height with respect to the user's mouth when the head-wearable device is worn by the user, the second height different than the first height; and
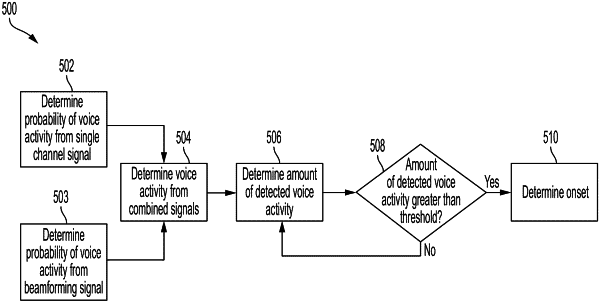
said determining whether the audio signal comprises the voice onset event comprises:
determining a first probability of voice activity with respect to the audio signal based on the first microphone output,
determining a second probability of voice activity with respect to the audio signal, wherein determining the second probability of voice activity comprises performing beamforming based on the first microphone output and the second microphone output, and
determining a combined probability of voice activity based on the first probability of voice activity and further based on the second probability of voice activity.
|