| CPC H04N 23/64 (2023.01) [G06V 10/774 (2022.01); G06V 10/776 (2022.01); G06V 10/945 (2022.01); H04N 5/77 (2013.01); H04N 13/207 (2018.05); H04N 23/632 (2023.01); G06V 2201/10 (2022.01)] | 20 Claims |
|
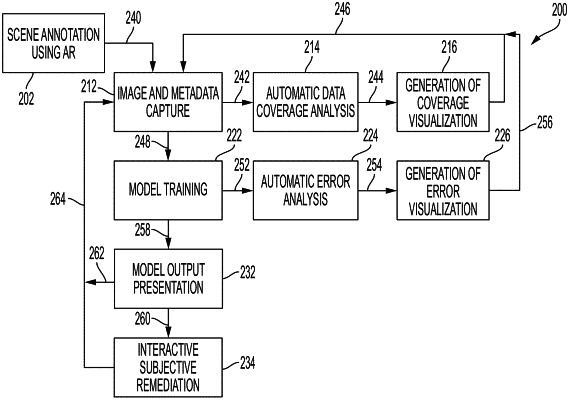
1. A computer-implemented method, comprising:
obtaining a plurality of images of a physical object captured by a recording device in a scene associated with a three-dimensional (3D) world coordinate frame;
measuring a level of diversity of the obtained images based on at least: a distance and angle between the recording device and the physical object in a respective image; a lighting condition associated with the respective image; an amount of blur associated with the physical object in the respective image; and a percentage of occlusion of the physical object in the respective image, wherein the percentage of occlusion is based on one or more of occlusions by other annotated objects in the respective image and whether any intersections exist with objects closer than a sample of points or a focal point of the physical object;
generating, based on the level of diversity, a first visualization of additional images which need to be captured by projecting, on a display of the recording device, first instructions for capturing the additional images using augmented reality (AR) features of the recording device;
training a model based on collected data which comprises the obtained images and the additional images;
performing an error analysis on the collected data by combining multiple folds of cross-validation in training the model to estimate an error rate for each image of the collected data; and
generating, based on the error analysis, a second visualization of further images which need to be captured by projecting, on the display, second instructions for capturing the further images,
wherein the further images are part of the collected data, and wherein the model is further trained based on the collected data.
|