| CPC G10L 21/013 (2013.01) [G10L 15/02 (2013.01); G10L 15/063 (2013.01); G10L 15/1807 (2013.01); G10L 19/028 (2013.01); G10L 19/032 (2013.01); G10L 21/04 (2013.01); G10L 25/24 (2013.01); G10L 25/30 (2013.01); G10L 25/90 (2013.01); G10L 2021/0135 (2013.01)] | 20 Claims |
|
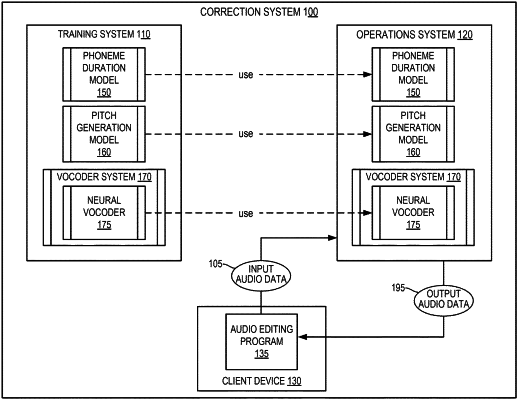
1. A method in which one or more processing devices perform operations comprising:
identifying, using a transcript of a speaker, audio data from an edit region of an audio recording of the speaker as distinct from an unedited audio portion of the audio recording, the audio data having a first prosody;
applying a phoneme duration model to the audio data to predict phoneme durations;
applying, using the phoneme durations, a pitch generation model to the audio data to provide a target prosody for the audio data, wherein the target prosody differs from the first prosody;
computing acoustic features representing samples, wherein computing respective acoustic features for a sample of the samples comprises:
computing a pitch feature as a quantized pitch value of the sample by assigning a pitch value of at least one of the target prosody or the audio data to at least one of a set of pitch bins, wherein each pitch bin of the set of pitch bins has an equal width in cents; and
computing, from the audio data, a periodicity feature and additional acoustic features for the sample,
wherein the respective acoustic features for the sample comprise the pitch feature, the periodicity feature, and the additional acoustic features;
applying a neural vocoder to the acoustic features to pitch-shift and time-stretch the audio data from the first prosody toward the target prosody to produce edited audio data; and
combining the edited audio data with the unedited audio portion of the audio recording.
|