| CPC G10L 15/065 (2013.01) [G10L 15/063 (2013.01); G10L 15/22 (2013.01); G10L 19/00 (2013.01)] | 20 Claims |
|
1. A system comprising:
a processing unit; and
a memory storage device including program code that when executed by the processing unit causes to the system to:
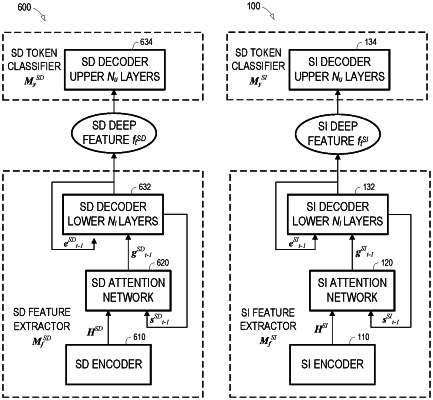
input first speech frames of a target speaker to an adapted speaker-independent attention-based encoder-decoder model; and
output token posteriors corresponding to the input first speech frames from the adapted speaker-independent attention-based encoder-decoder model,
the adapted speaker-independent attention-based encoder-decoder model having been generated by training a speaker-independent attention-based encoder-decoder model to classify output units based on second input speech frames, the trained speaker-independent attention-based encoder-decoder model associated with a first output distribution, and by adapting the trained speaker-independent attention-based encoder-decoder model to classify output tokens based on input speech frames of the target speaker while simultaneously training the trained speaker-independent attention-based encoder-decoder model to maintain a similarity between the first output distribution and a second output distribution of the adapted speaker-independent attention-based encoder-decoder model.
|