| CPC G09B 5/06 (2013.01) | 24 Claims |
|
1. A computer-implemented method for providing, on a user computer, a virtual puzzle comprising a plurality of virtual puzzle pieces placeable in corresponding puzzle slots to collectively form a target;
wherein either: each of the plurality of virtual puzzle pieces comprises at least one letter, and the target comprises a target word; or, the plurality of virtual puzzle pieces comprises a plurality of words, and the target comprises a sentence;
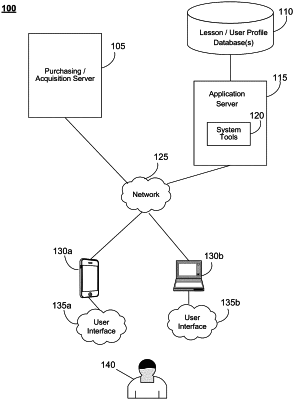
wherein the user computer comprises a display screen, an audio transducer, and an input device;
the method comprising the steps of:
(a) displaying, on the display screen, the plurality of virtual puzzle pieces displaced from their corresponding puzzle slots, wherein the plurality of virtual puzzle pieces are movable on the display screen with use of the input device; and
(b) in response to the input device selecting any one of the plurality of virtual puzzle pieces while the selected virtual puzzle piece is displaced from its corresponding puzzle slot, causing the user computer to generate in real-time a selection sensory feedback comprising:
the display screen persistently displaying an animation of the selected virtual puzzle piece while the input device is moving the selected virtual puzzle piece and the selected virtual puzzle piece is displaced from its corresponding puzzle slot; and
the audio transducer outputting a vocalization of the selected virtual puzzle piece, wherein the vocalization is mapped by a database to the selected virtual puzzle piece, and
wherein the vocalization comprises either: a phonetic sound of the selected virtual puzzle piece when the selected puzzle piece comprises at least one letter and the target comprises the target word; or a pronunciation of the selected virtual puzzle piece when the selected puzzle piece comprises one of the plurality of words and the target comprises the sentence.
|